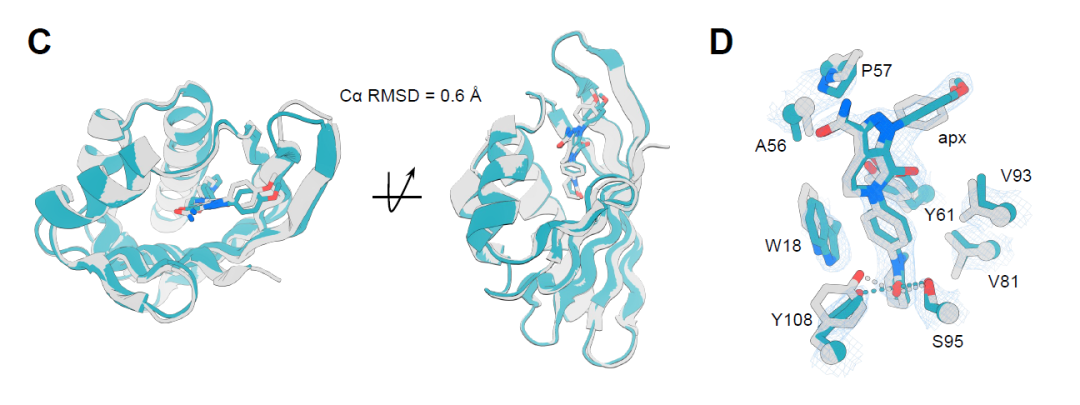
韩国科学技术院的研究团队利用深度学习设计了能够选择性识别压力激素皮质醇的小分子结合蛋白,并开发了人工智能生物传感器。这项研究突破了传统蛋白质设计的局限,提供了高特异性和高亲和力的蛋白质定制方法,具有广泛的应用潜力,如疾病诊断和新药研发。研究成果已发表在《Nature Communications》上。
蛋白质结合剂在疾病诊断和药物递送中至关重要。阿布扎比和硅谷的研究团队提出的新模型Prot42,仅依赖蛋白质序列生成高亲和力结合剂,显著提高了蛋白质设计的效率。
本研究解决了医疗数据中大量缺失值导致的时间序列插补问题。提出的ImputeINR方法利用隐式神经表示来学习时间序列的连续函数,从而能够在数据稀疏的情况下生成高质量的插补。实验结果显示,ImputeINR在高缺失率情况下的插补性能优于现有方法,并且提高了下游疾病诊断任务的表现。
本研究提出了一种基于人工智能的肾脏异常分割算法,旨在提高临床评估的客观性。该算法经过验证,能够在不同患者中保持高性能,从而增强肾脏疾病的评估和诊断能力。
罕见病因其患病率低和知识匮乏,常导致误诊和延迟诊断。研究者开发了多智能体对话框架(MAC),通过多个智能体协作提升诊断能力。基于GPT-4的MAC在302例罕见病的诊断中表现优于单一智能体,能够生成更丰富的诊断内容,成为医生的重要辅助工具。
本研究提出了一个农作物疾病诊断的多模态数据集(CDDM),包含137,000张图像和100万个问答对,结合视觉与文本数据,提升农业专家的诊断能力。通过低秩适应微调策略,显著提高了多模态模型在疾病诊断中的表现。
本研究解决了现有检索增强方法在评估任务难度和检索决策方面的不足,无法满足临床效率与准确性的平衡需求。提出的FIND框架通过引入细粒度自适应控制模块,根据输入的信息密度判断是否需要检索,从而优化检索过程,并在临床场景中提高可靠性。实验结果显示,FIND在三个中国电子病历数据集上明显优于多种基线方法,展示了其在临床诊断任务中的有效性。
本文提出了一种可学习多视角对比框架(LMCF),旨在降低医学时间序列疾病诊断中的高注释成本,并克服现有对比学习方法的局限性。该框架利用多头自注意力机制和适应性学习不同视角的表示,结合预训练的AE-GAN重建目标数据中的差异,显著提升了心肌梗死、阿尔茨海默病和帕金森病等诊断任务的准确性和泛化能力。
近年来,英伟达和谷歌等科技巨头加大对AI医疗的投资,推动医学大模型研发,应用于疾病诊断和医学图像处理。2023-2024年间,多篇前沿论文展示了AI在糖尿病和癌症管理中的应用,显著提升医疗效率和患者体验。
医疗人工智能的发展依赖于高质量的数据集,涵盖疾病诊断、药物研发和个性化医疗等领域。本文整理了10个医学数据集,包括中医药、医学问答和推理,旨在帮助研究人员了解数据资源的特点与应用。
2012年,谢伟迪从通信领域转向计算机视觉,专注于医疗人工智能。他认为通用医疗AI系统能够整合多模态数据,促进疾病诊断。团队利用网络爬虫收集医学数据,构建多模态模型,强调知识驱动的重要性,未来将关注临床需求和基因组学研究。
近年来,英伟达和谷歌等科技巨头加大对AI医疗的投资,推动医学大模型研发,应用于疾病诊断和医学图像处理。2023-2024年间,研究者发布多项前沿论文,涉及糖尿病、癌症等疾病的AI诊断技术,显著提升医疗效率和患者体验。
2024年,人工智能与结构生物学的结合取得重要突破,推动了生命科学研究的新机遇。AI在蛋白质结构预测和生物医药领域的应用,显著提升了药物研发和疾病诊断的效率,促进了基础生物学的深入探索。
研究表明,ChatGPT在疾病诊断中的准确率达到90%,远超人类医生的74%。与医生合作时,准确率为76%。OpenAI总裁强调人机合作需加强,实验结果显示AI潜力巨大。
本研究提出了ClinRaGen小型语言模型,结合领域知识与电子健康记录数据,解决了现有模型在疾病诊断中忽视生成支持性推理的问题。研究表明,ClinRaGen显著提升了多模态数据处理和临床推理生成的准确性,推动了医疗应用的发展。
本研究探讨大型语言模型(LLMs)在医疗领域的应用,特别是在电子健康记录和疾病诊断中的有效性与可靠性。研究表明,LLMs在处理语义问题时表现优于数值问题,但仍不及人类,需谨慎对待其医疗建议。提出了Two-phase Verification方法以提高生成信息的可靠性,并强调模型选择与数据特征的重要性。
本研究针对现有医学人工智能模型在不同临床环境中的泛化能力不足问题,提出了CXRBase,一个从未标记的胸部X光影像中学习通用表示的基础模型。通过自监督学习,CXRBase能够识别有意义的模式,并经过调优后在疾病检测中表现出色,显著提升模型性能,同时减轻专家的标注工作负担,推动胸部影像的广泛临床应用。
本文探讨了MentalBERT和MentalRoBERTa等预训练语言模型在精神健康领域的应用,评估其在精神障碍检测中的表现。研究表明,针对特定领域的预训练有助于提高检测性能。大型语言模型(如GPT-4)在心理健康护理中展现出潜力,但需谨慎使用,强调人类辅导员的不可替代性。此外,研究提出了评估框架和患者模拟工具,以提升心理健康培训效果。
该论文研究高维高斯图形模型的估计问题,提出基于节点扰动和公共中心节点的假设,并利用凸优化和多重乘数算法进行解决。研究结合图卷积神经网络以应对基因表达数据不足的问题,并展示了基于贝叶斯方法和图变分贝叶斯推断在基因调控网络推断中的应用,强调网络结构对聚类结果的影响,为疾病诊断提供基础。
本研究提出了一种基于提示学习框架的知识增强方法,通过整合外部知识到提示模板中,提高语言模型的理解和推理能力。实验结果表明,该方法在多个数据集上显著提升了疾病诊断的准确性和可解释性。
完成下面两步后,将自动完成登录并继续当前操作。