
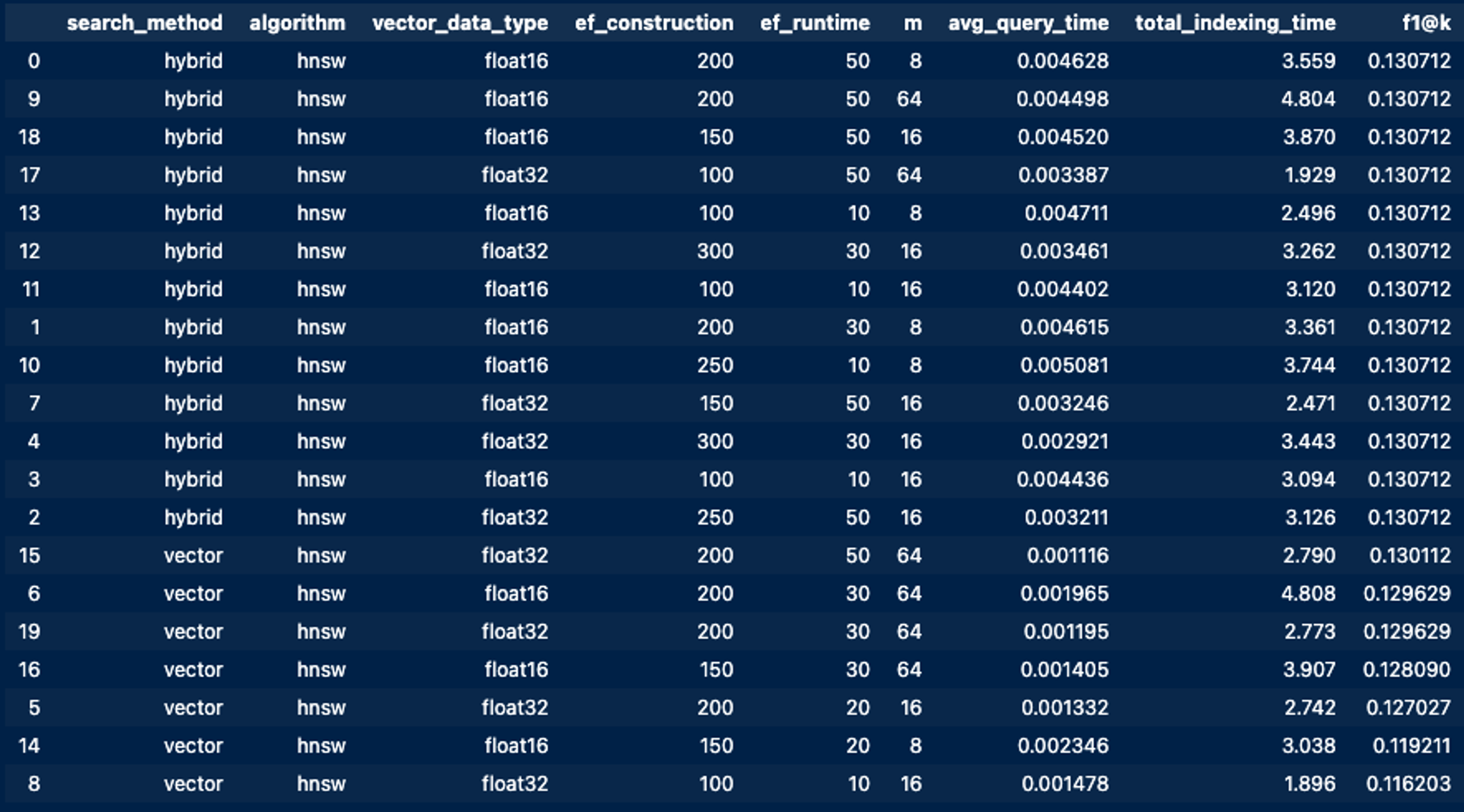
检索优化器:贝叶斯优化
Redis Blog
·

通过方向修正解释和改进最优控制问题
Apple Machine Learning Research
·
网络上的模仿正则化最优输运:可证明的鲁棒性与物流规划应用
BriefGPT - AI 论文速递
·
通过策略空间中的最优传输测量强化学习中的探索
BriefGPT - AI 论文速递
·
