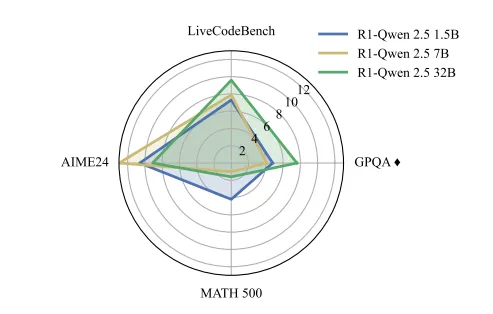
大模型推理路由难题反而催生稀疏注意力?
极道
·
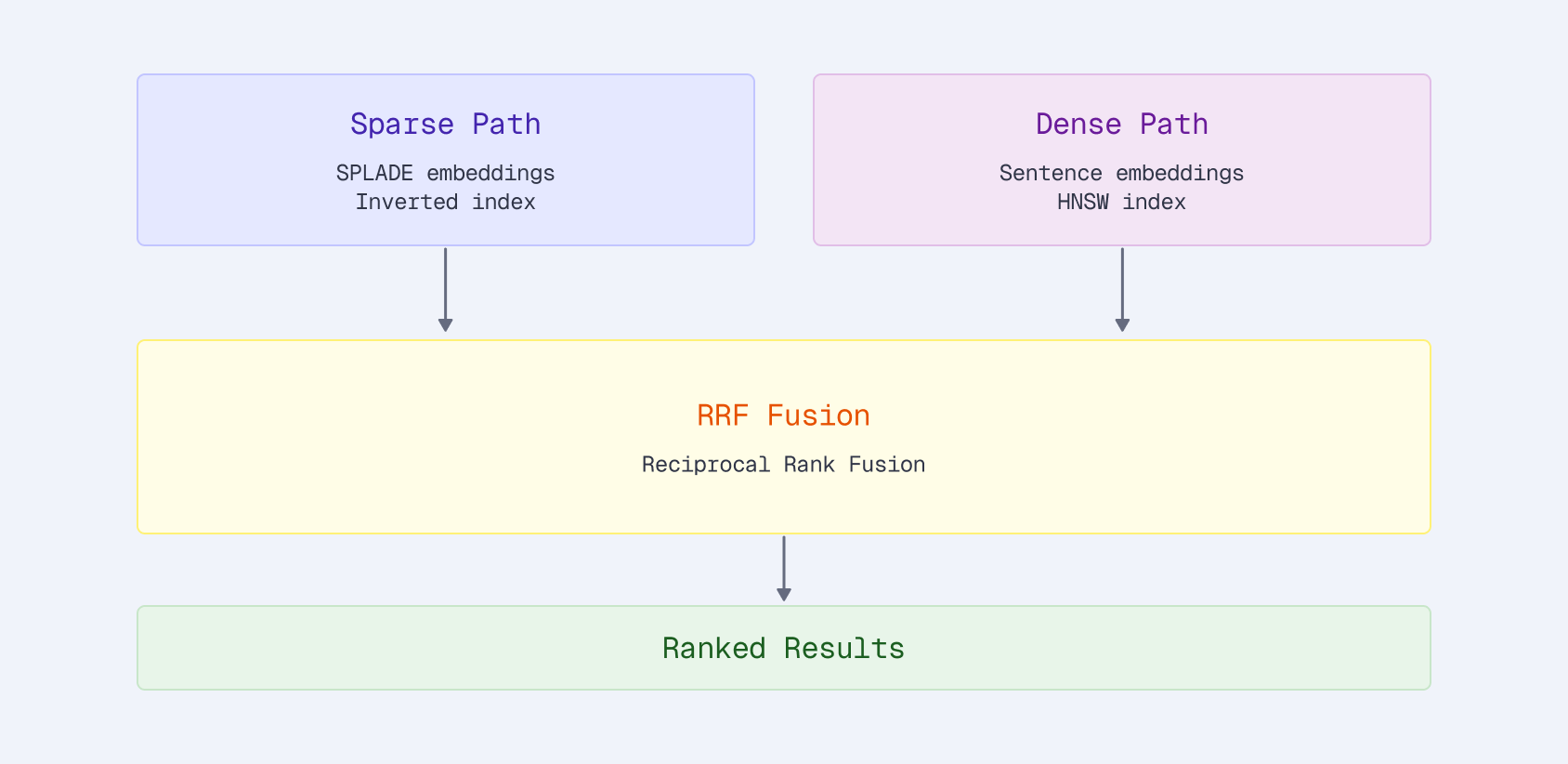
电子商务搜索中的稀疏嵌入微调 | 第3部分:评估与困难负样本
Qdrant - Vector Database
·
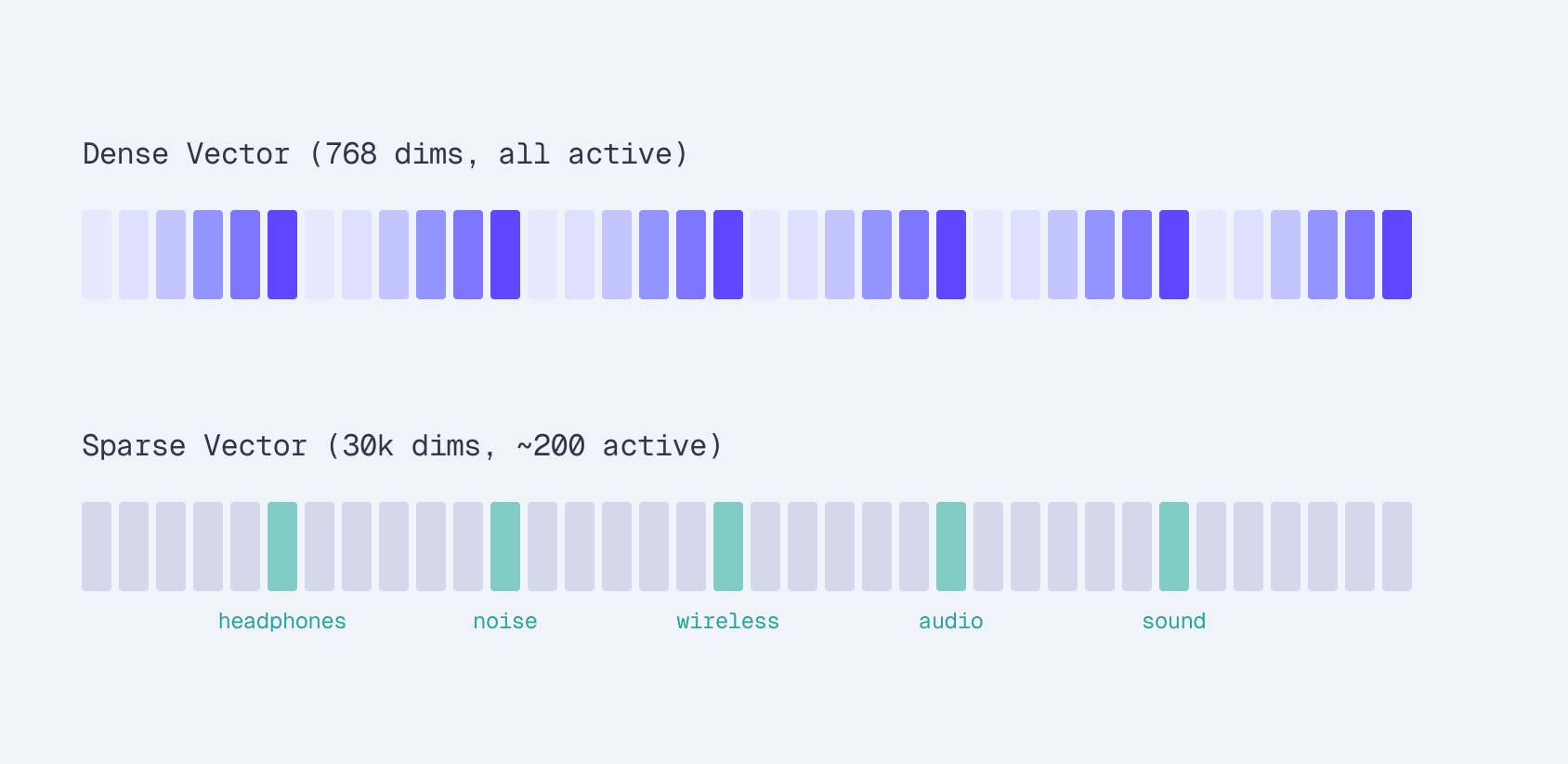
电子商务搜索中的稀疏嵌入微调 | 第1部分:稀疏嵌入为何优于BM25
Qdrant - Vector Database
·
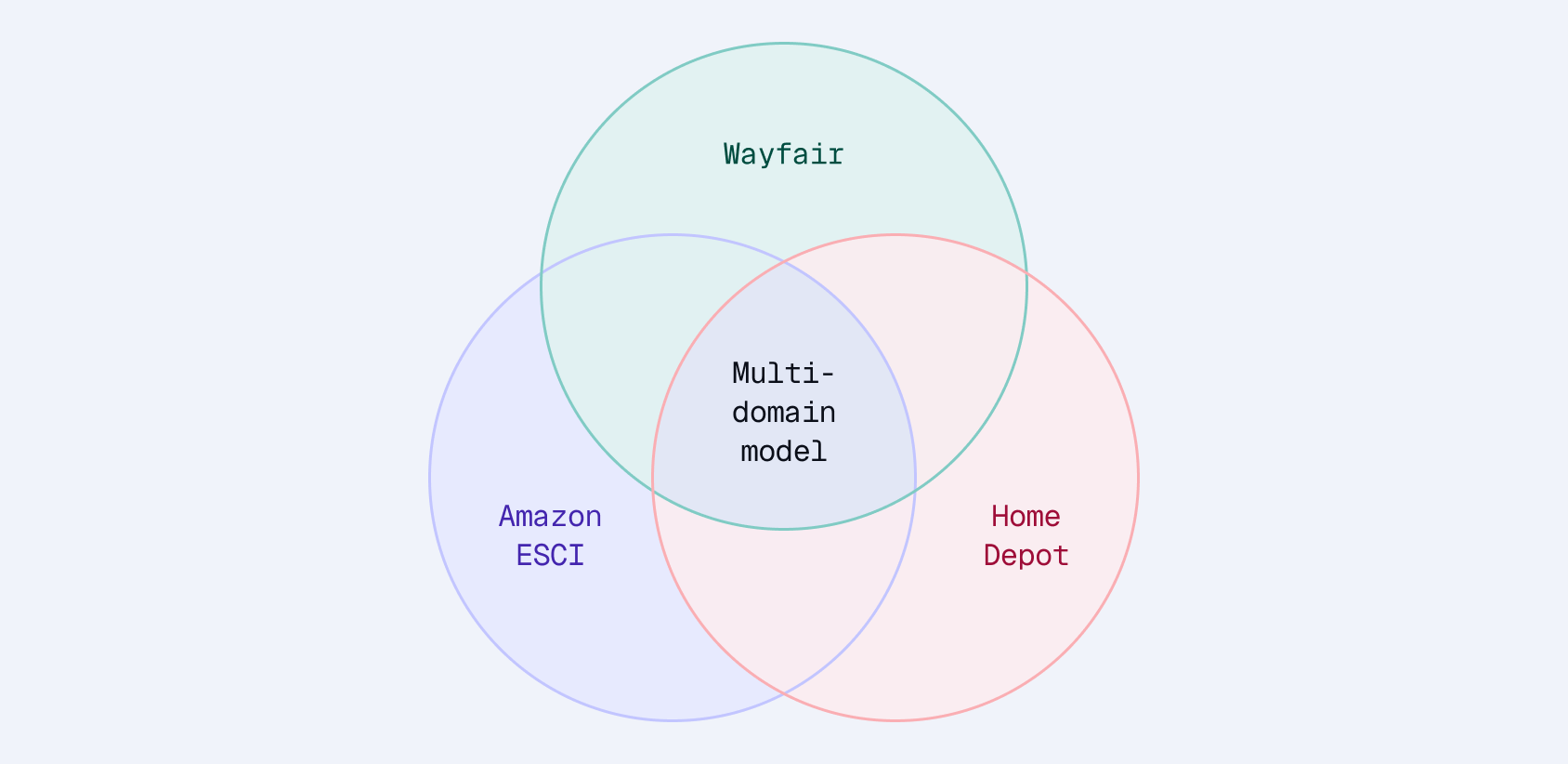
电子商务搜索中的稀疏嵌入微调 | 第4部分:专业化与泛化
Qdrant - Vector Database
·
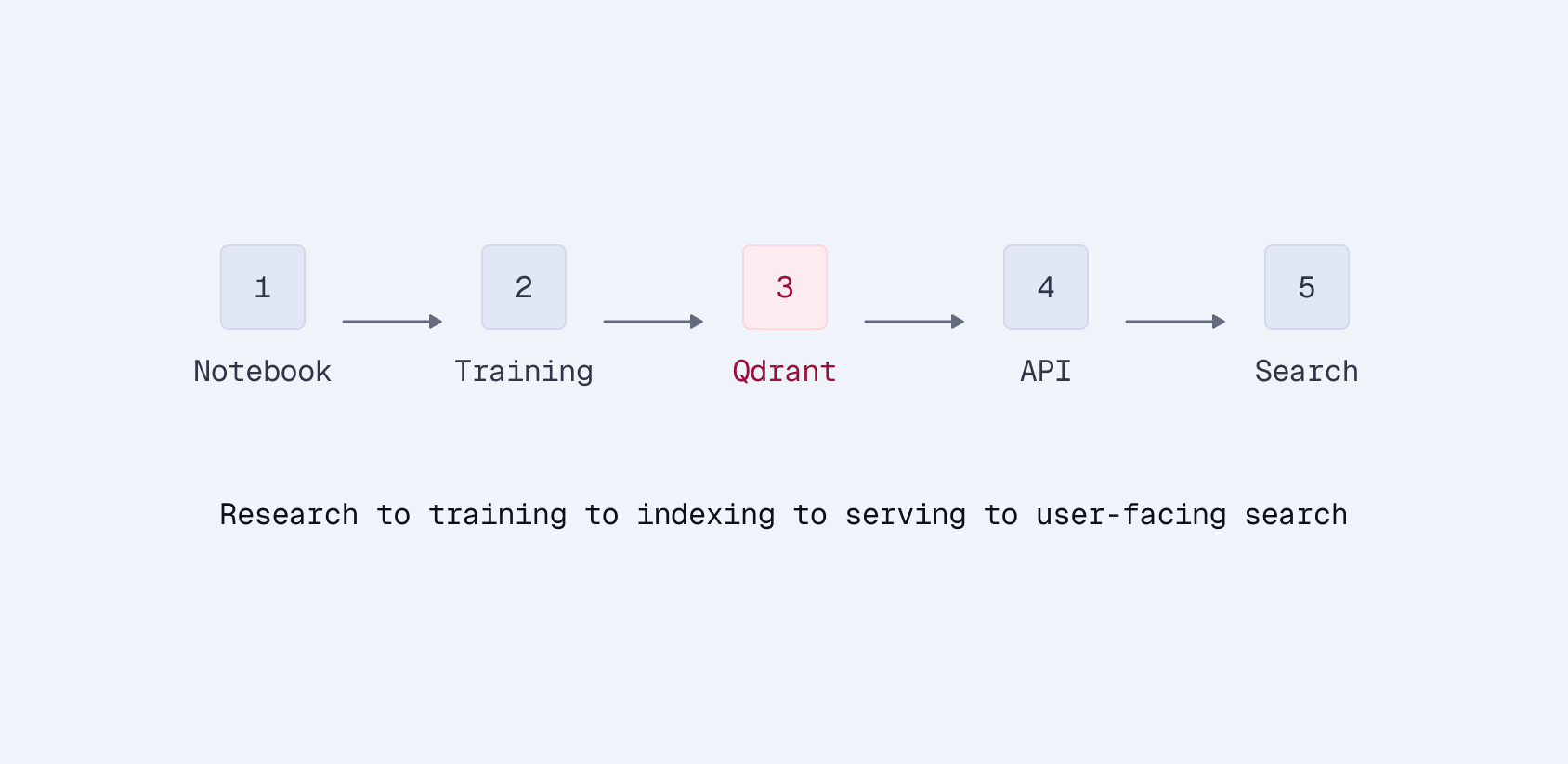
电子商务搜索中的稀疏嵌入微调 | 第5部分:从研究到产品
Qdrant - Vector Database
·

电子商务搜索中的稀疏嵌入微调 | 第二部分:在Modal上训练SPLADE
Qdrant - Vector Database
·
专为提升注意力计算,提供稀疏与密集核函数 | 开源日报 No.863
开源服务指南
·


PREAMBLE:通过块稀疏向量实现私密高效聚合
Apple Machine Learning Research
·

vLLM中的DeepSeek-V3.2-Exp:细粒度稀疏注意力的应用
vLLM Blog
·
屏蔽扩散:利用稀疏排斥生成新颖多样的图像
Apple Machine Learning Research
·