
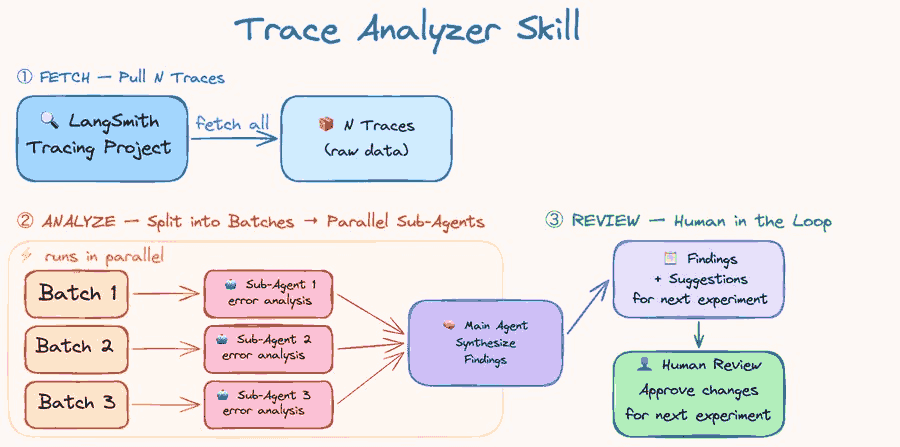
Langchain 团队如何评估与优化 agent harness
Measure Zero
·
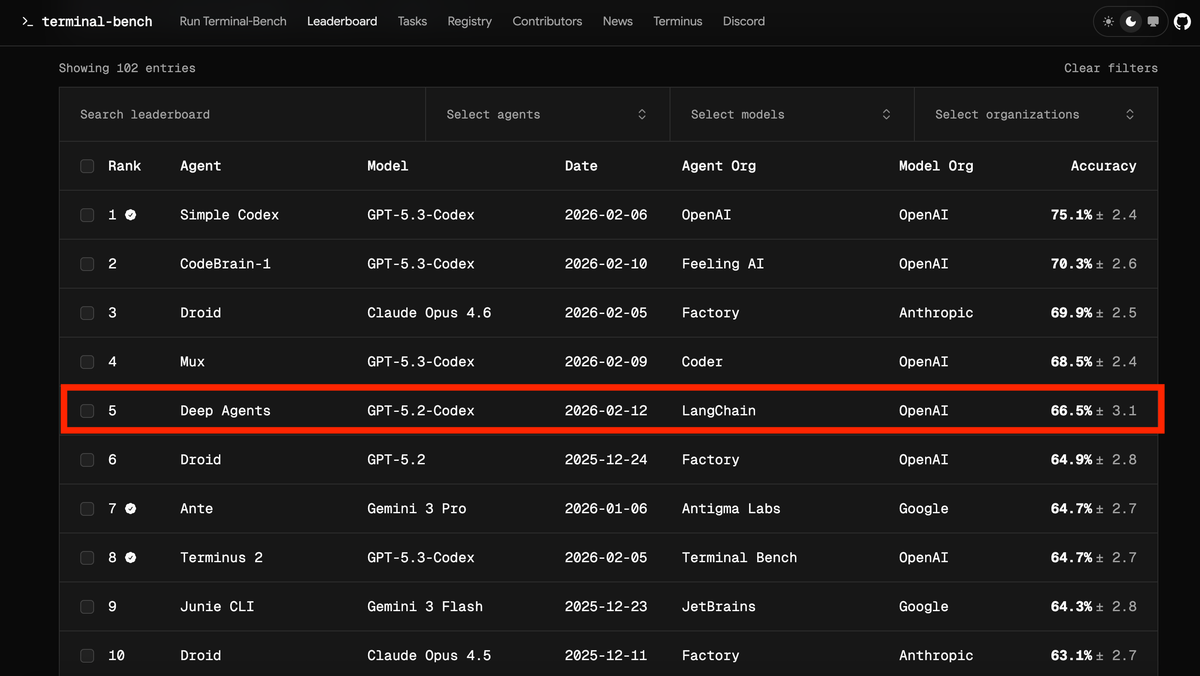
通过哈希工程提升深度代理的性能
LangChain Blog
·



研究表明,AI模型通过检查多个答案变得更智能
DEV Community
·

基于AI的知识挖掘系统利用多个代理以更高的准确性提取数据
DEV Community
·

OpenAI推出o3 - 具备推理能力的生成模型家族
DEV Community
·

