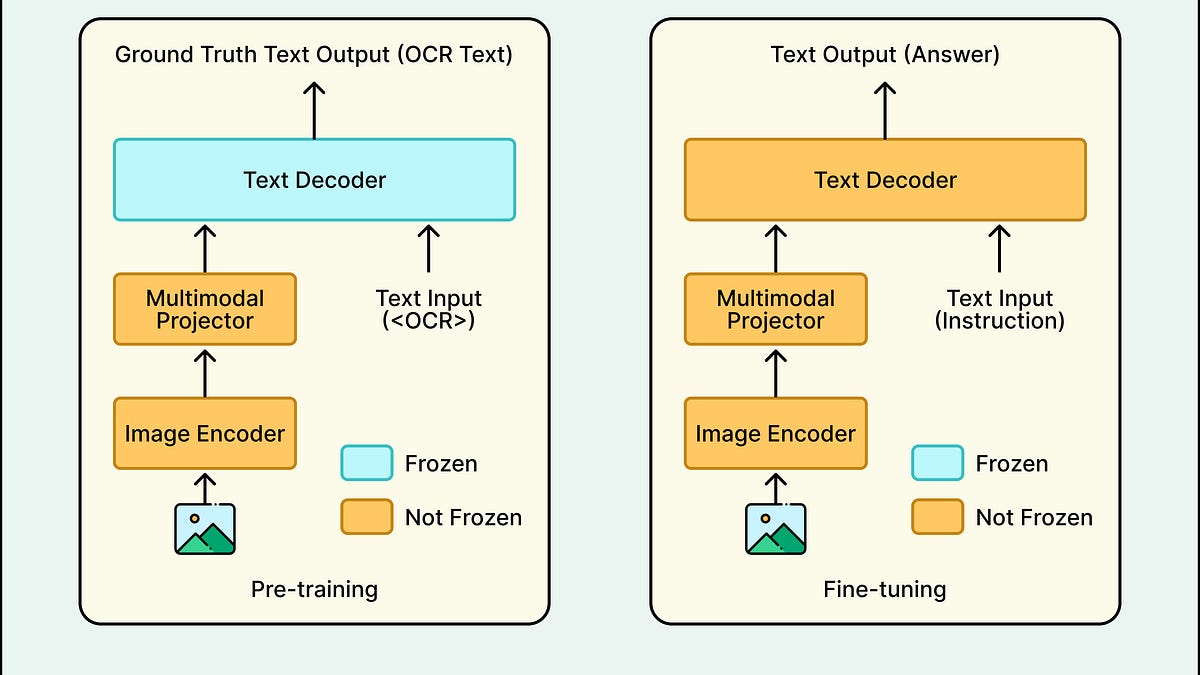
Grab团队开发了一种轻量级视觉大语言模型(Vision LLM),旨在提升东南亚语言的文档处理能力。通过合成数据和自动标注框架Documint,优化了OCR和关键信息提取的准确性,最终模型在准确性和延迟方面表现优异,展示了专用模型在文档处理中的潜力。
计算机视觉国际大会(ICCV)是顶级会议之一,专注于视频理解和多模态推理,涵盖时间表示、实时对话生成和视觉大语言模型等研究,推动了计算机视觉领域的发展。
该研究提出了REVEAL框架,用于评估复杂视觉大语言模型(VLLMs)在多模态和多轮对话中的图像输入风险。研究表明,多轮交互的缺陷率高于单轮评估,尤其在处理错误信息时表现脆弱,提示需加强防御措施。
本文探讨了视觉大语言模型(VLLMs)在视觉、动作和语言等领域的应用,分析了其使用场景、伦理考量及面临的挑战,并提出未来的发展方向。
本研究提出了一种新评估方法,解决视觉大语言模型在视觉空间推理(VSR)数据集不足的问题。改进后的模型VSRE在VSR测试集上的准确率提高超过27%,为该领域研究提供了新思路。
本研究探讨视觉大语言模型(VLLM)在越狱攻击下的脆弱性,指出现有防御机制过于谨慎,可能在良性输入时意外放弃效果。同时,常用的越狱评估方法可能误导攻击策略和防御机制的评估,呼吁重新审视基准数据集和防御策略。
本研究提出了一种名为CL-HOI的跨层人机交互蒸馏框架,旨在减少对人工标注的依赖。通过从视觉大语言模型中提取交互信息,CL-HOI在HICO-DET和V-COCO数据集上表现优于传统方法,验证了其在无标注条件下的有效性。
本文提出了一种基于蒸馏的多模态对齐模型,通过偏好调优和自动生成数据的方法解决视觉大语言模型中的幻觉问题。研究探讨了大型语言模型的偏差,提出了OPEN框架以优化用户偏好获取,并介绍了因果偏好优化(CPO)和相对偏好优化(RPO)等新方法,显著提升了模型性能和适应性。
完成下面两步后,将自动完成登录并继续当前操作。