Google DeepMind与牛津大学及UCL的研究团队提出了D4RT模型,旨在高效重建动态视频中的4D场景。该模型通过单次视频输入,利用灵活的查询机制,独立获取任意点的三维状态,显著提高了推理速度和效率,刷新了多项基准测试记录,为未来的4D视觉感知提供了新的范式。
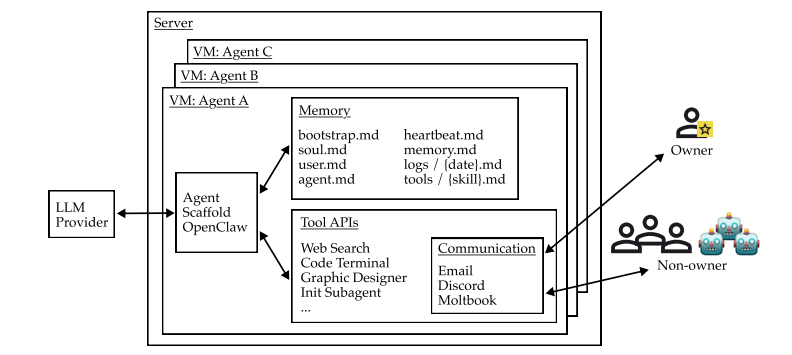
元萝卜通过OpenClaw项目实现了AI与现实世界的交互,推动了桌面智能体的发展。该项目结合视觉感知与机械臂,能够执行抓取和摆放等任务,拓展了AI的应用场景,模糊了虚拟与现实的界限。
科学家们开发了SemVideo系统,能够从fMRI大脑信号重建观看的视频。该技术通过分层语义信息指导重建,推动了脑机接口和视觉感知研究的发展。尽管存在设备昂贵和视频质量不足的局限,SemVideo为未来沟通方式带来了新可能。
抖音SAIL团队与LV-NUS Lab联合推出的SAIL-VL2多模态大模型在106个数据集上取得了显著突破,尤其在复杂推理任务中表现出色。该模型通过创新架构和数据处理,展现了小参数规模模型的强大能力,具备细粒度视觉感知和复杂推理能力,成为开源领域的领先者。
AI Agent 通过与计算机和物理环境的互动,执行复杂任务并重塑自动化与人机交互。它们利用视觉感知和上下文理解,能够像人类一样操作图形用户界面,从而提升工作效率。主要项目如 Google Project Astra 和 OpenAI 的 ChatGPT Agent 展示了这些技术的潜力,推动了主动式、情境感知型 AI 伙伴的发展。
本文讨论了VisualMimic框架在类人机器人行走与操作中的应用,通过分层设计提升强化学习的泛化能力。该框架结合低层关键点跟踪与高层视觉运动策略,使机器人在真实环境中执行多样化任务,展现出良好的鲁棒性和适应性。研究强调自我中心视觉感知与全身灵巧性的结合,推动了人形机器人在物体交互方面的进展。
LOVON系统结合大语言模型与开放词汇视觉感知,旨在提升足式机器人在复杂环境中的长时任务执行能力。通过拉普拉斯方差滤波技术,LOVON解决了视觉不稳定性,实现了动态目标下的自主导航与任务规划。
本文介绍了VITAL策略学习框架,通过将操作任务分为到达和局部交互两个阶段,结合视觉和触觉感知,提高机器人在精细操作中的成功率和泛化能力。VITAL利用视觉-语言模型进行目标定位,并通过触觉反馈实现高精度操作,克服了模仿学习和强化学习的局限性。
UC伯克利等团队研发的LeVERB框架首次实现人形机器人视觉感知与运动控制的结合,机器人能够根据语言指令自动完成复杂动作。在Unitree G1机器人上测试,零样本成功率达到80%,整体任务成功率为58.5%,显著优于传统方法。
上海AI实验室推出VeBrain通用智能大脑,集成视觉感知、空间推理和机器人控制,实现机器人像人类一样的“看到-思考-行动”。该模型通过关键点检测和技能识别,提升多模态理解与控制能力,测试结果显示其在多个任务中表现优异。
本研究提出了一种三重层次扩散策略(H$^{3}$DP),有效解决视觉感知与动作预测的耦合问题。H$^{3}$DP在44个仿真任务中性能提升27.5%,并在4个双手操作任务中表现优异,显示出其潜在影响。
本研究提出了一种自适应标记语言生成方法,旨在解决视觉文档理解中视觉感知与文本理解的整合问题。该模型在复杂文档布局下表现优异,显著提升了视觉场景的推理和理解能力。
Perception-R1是由多所高校联合开发的多模态大语言模型,首次在COCO2017验证集上实现30AP,超越YOLOv3等模型。该模型通过强化学习优化视觉感知策略,提升了物体检测、计数和OCR等任务的能力,为AI视觉感知的未来奠定基础。
UFO是一种新型多模态大模型,通过特征检索实现细粒度视觉感知,无需额外解码器,表现优异,支持文本输出,简化任务复杂性,提升性能。
本研究提出了一种模块化视觉对比解码(MVCD)框架,旨在提升大型语言模型(LLMs)在多模态任务中的表现。MVCD通过利用LLMs的上下文学习能力,有效提高了视觉感知能力和模型准确性,展现出重要的应用潜力。
本研究探讨了大型视觉语言模型中的幻觉现象,提出了视觉感知头发散指标,量化注意力头对视觉内容的敏感性,并引入视觉感知头强化方法,显著改善了模型表现。
本研究提出了综合性基准VL-RewardBench,用于评估视觉-语言生成奖励模型(VL-GenRMs)。通过高质量样本选择与人工验证,发现该基准能够揭示模型在视觉感知任务中的失误,并与其他测评结果高度相关,为改进VL-GenRMs提供了重要见解。
本研究首次将后门攻击应用于机器人视觉感知模块,证明其能够有效误导机器人臂的操作,揭示了潜在的安全威胁。
本研究提出了一种新的记忆型视觉-本体感知强化学习模型,旨在提高机器人推物的精确度,减少修正动作,增强其在日常生活中的辅助能力。
本研究探讨了扩散模型在生成和视觉感知任务中的应用,提出了一种将深度估计、光流和分割统一为图像转换的高效训练技术。结果表明,该模型在数据和计算资源较少的情况下,性能与先进方法相当。
完成下面两步后,将自动完成登录并继续当前操作。