

像素化!设计系统中视觉一致性的网络简易指南
Blog Awesome
·


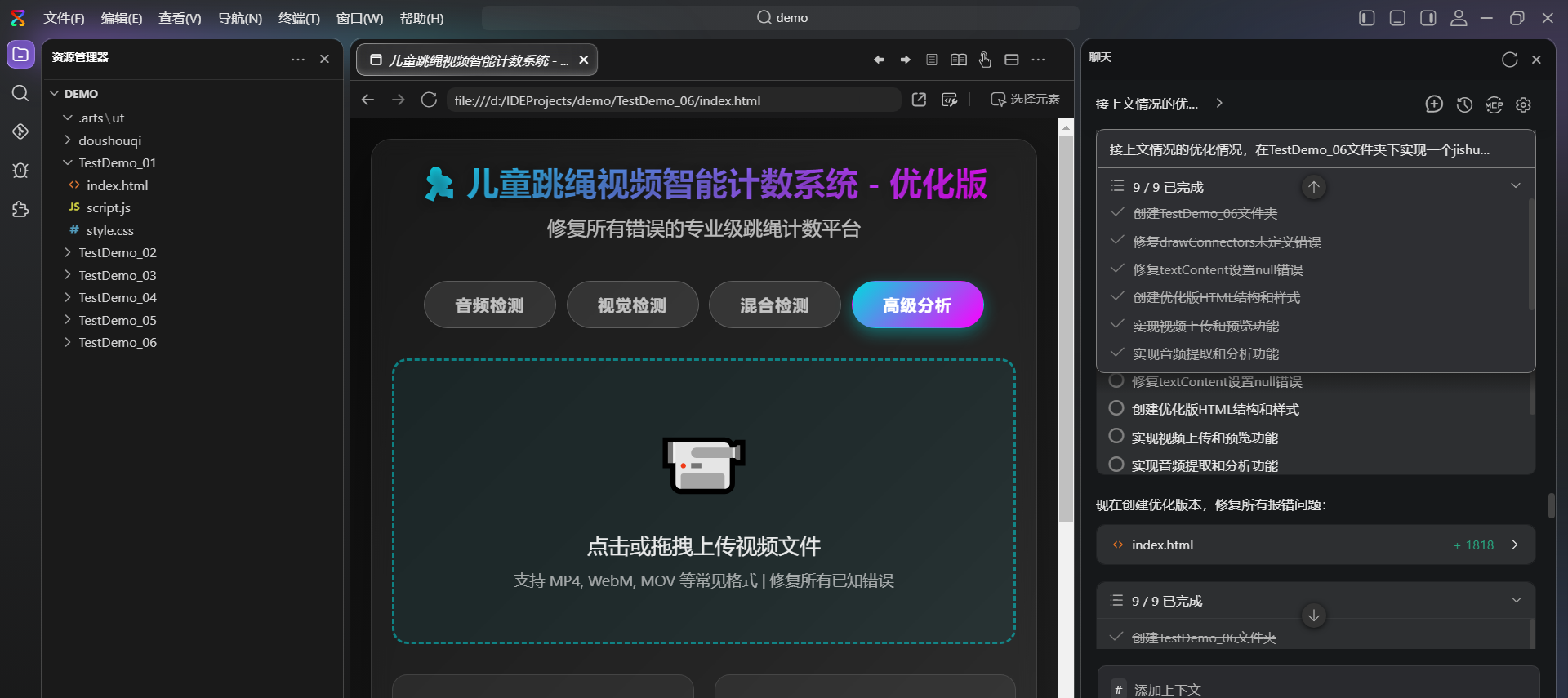
【案例共创】码道小工匠,儿童跳绳智能计数系统开发实战
华为云官方博客
·

多模型智能识别平台还能这么玩?.NET 10 + YOLO + AI 解锁工业级视觉应用新姿势
dotNET跨平台
·

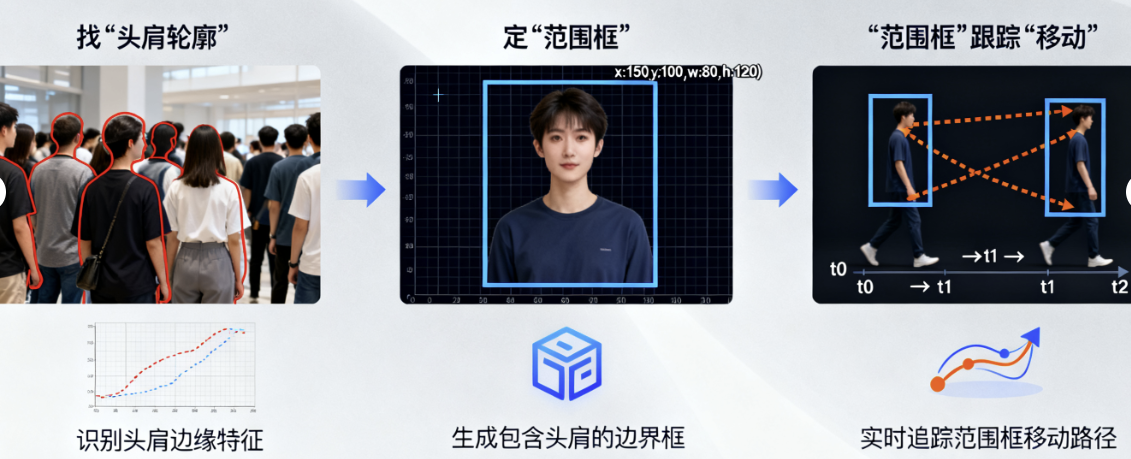

《我看见的世界:李飞飞自传》
Frytea's Blog
·


10个激发灵感的平面设计项目创意
Design Shack
·

字体心理学:排版如何塑造品牌认知
Design Shack
·


