
【AI入门课程系列】5、AI 如何看见东西?—— 机器视觉
内容提要
AI通过摄像头捕捉图像,利用视觉算法提取特征并与记忆库对比,实现物体识别。传统模型专注于单一物体识别,而大模型能够同时识别多种物体并灵活判断新图像。
关键要点
-
AI通过摄像头捕捉图像,利用视觉算法提取特征并与记忆库对比,实现物体识别。
-
AI的“眼睛”是摄像头等设备,抓取画面并将其转化为数字图片。
-
AI的视觉算法通过拆解图像找出关键特征,类似于拼图游戏。
-
AI通过对比特征与记忆库中的模板来判断物体是否识别成功。
-
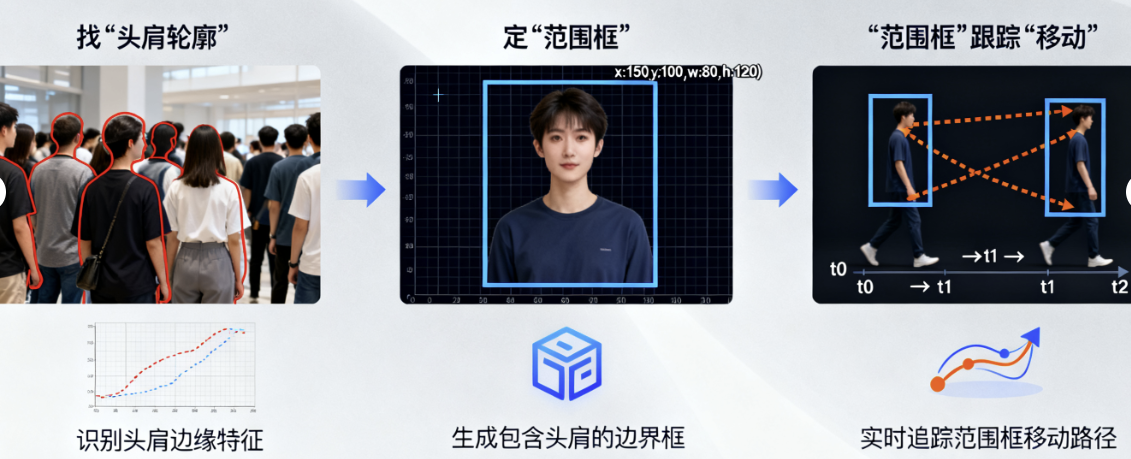
传统机器视觉算法专注于单一物体识别,如人脸识别、头肩检测和手势识别。
-
大模型视觉识别能够同时识别多种物体,具备灵活判断新图像的能力。
-
大模型通过学习大量图像和总结通用规律来提高识别能力。
-
生活中的应用包括图识物APP、AI批改作业和自动驾驶技术。
-
AI的识别过程与人类学习认物的过程相似,传统模型偏向专项练习,大模型则是综合学习。
延伸解读
机器视觉的基本原理
AI的视觉识别过程可以分为三个步骤:抓取画面、拆解特征和对比判断。这一过程与人类的视觉认知相似,首先通过摄像头捕捉图像,然后提取关键特征,最后与记忆库中的模板进行对比。这种方法使得AI能够在复杂环境中进行物体识别,具有较高的准确性。
传统模型与大模型的对比
传统机器视觉模型通常专注于单一物体的识别,如人脸或手势,适用范围有限。而大模型则能够同时识别多种物体,并通过学习大量图像总结通用规律,具备更强的灵活性和适应性。这种转变使得AI在实际应用中更加高效,能够处理更复杂的任务。
实际应用场景
AI的视觉识别技术在生活中有广泛应用,如图识物APP、AI批改作业和自动驾驶技术等。这些应用不仅提高了效率,还为用户提供了便利。了解这些应用场景可以帮助我们更好地理解AI技术的实际价值和潜力。
延伸问答
AI是如何捕捉图像的?
AI通过摄像头等设备抓取画面,将其转化为数字图片。
AI的视觉算法是如何工作的?
AI的视觉算法通过拆解图像找出关键特征,并与记忆库中的模板对比来实现物体识别。
传统机器视觉算法与大模型视觉识别有什么区别?
传统机器视觉算法专注于单一物体识别,而大模型视觉识别能够同时识别多种物体并灵活判断新图像。
AI如何进行物体识别的判断?
AI通过对比特征与记忆库中的模板,如果特征匹配成功,就认出物体;否则就说“没见过”。
大模型视觉识别的优势是什么?
大模型视觉识别能够学习大量图像并总结通用规律,从而提高识别能力,灵活判断新图像。
AI在生活中有哪些应用?
AI的应用包括图识物APP、AI批改作业和自动驾驶技术等。
