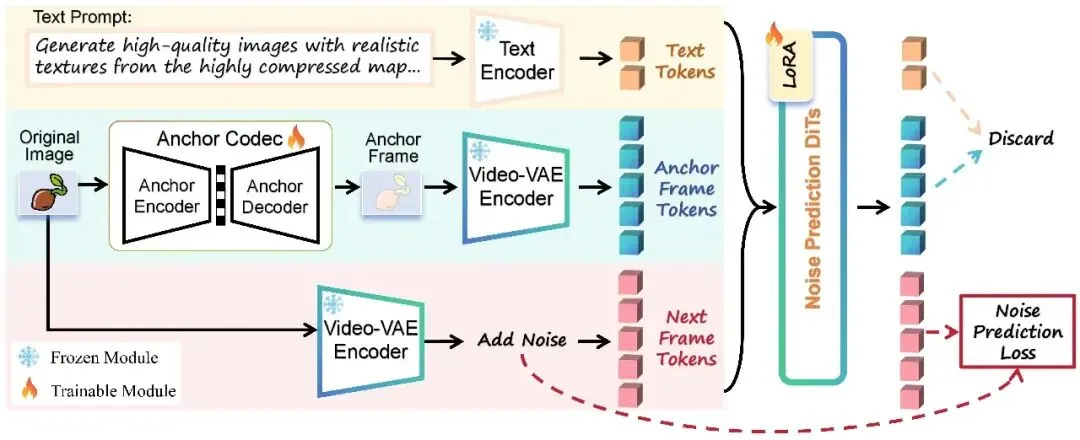
本文介绍了一种新型超低码率图像压缩方法NeFIC。该方法通过解码锚点帧并利用视频扩散模型进行下一帧预测,提高了解码效率和图像质量。实验结果表明,NeFIC在多个测试集上显著降低了码率,同时保持高感知质量和真实感,节省超过50%的码率。
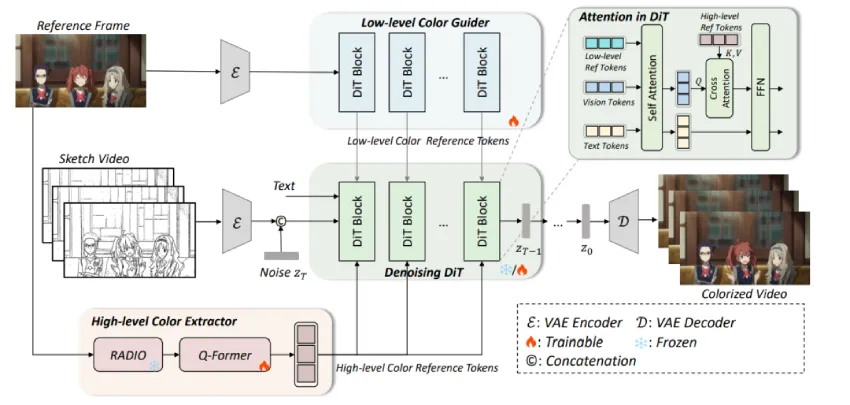
本文提出了一种新型动画上色模型ColorAnime,基于视频扩散模型,能够根据参考图像自动将草图序列转化为高质量彩色动画。该模型通过高低层次颜色提取器实现颜色一致性和细粒度控制,克服了现有方法在大幅运动场景中的不足,实验结果表明其在颜色准确性和视频质量方面表现优异。
本研究提出VideoPanda方法,解决虚拟现实中高分辨率全景视频生成的挑战。该方法通过多视角注意力层增强视频扩散模型,实现基于文本或单视角视频生成一致的多视角视频,生成的360°全景图像更真实连贯。
清华大学研究团队提出了VideoScene,一种专注于3D场景生成的“一步式”视频扩散模型。该模型通过3D跃迁流蒸馏策略加速推理,并结合动态降噪策略,提高生成效率和质量。实验结果表明,VideoScene在速度和质量上均优于现有模型,具有广泛的应用潜力。
本研究提出了一种新颖的两阶段图像到视频生成框架,旨在解决视频扩散模型在生成物理可行视频时缺乏物理理解的问题。该框架有效捕捉物理运动,为视频生成领域带来新视角和改进。
本研究提出了一种视频扩散模型,解决了3D重建与生成之间的条件缺口,提升了生成模型的训练效果,并验证了其在稀疏视图和遮挡输入下的视图合成有效性。
本研究提出了多视角视频扩散模型SV4D 2.0,旨在解决动态3D资产生成中的时空一致性问题。通过改进网络架构和训练策略,SV4D 2.0在遮挡和大运动情况下表现更为稳健,显著提升了视频的细节清晰度和时空一致性。
本研究提出了一种新方法Zero-1-to-A,旨在解决动画头像生成中的数据量过大问题。通过视频扩散模型构建一致性数据集,实现4D头像重建,优化头像质量。实验结果表明,该方法在真实感、动画质量和渲染速度上优于现有技术。
本研究提出了一种可扩展的开源视频基础模型(VFM)训练流程,旨在解决大规模、高质量视频模型训练中的挑战。该流程加速了视频数据集的策划,支持多模态数据加载,并实现了视频扩散模型的并行训练和推理,显著提升了训练效率和推理性能。
复旦大学团队在《ACM Computing Surveys》上发表了一篇关于视频扩散模型的综述,涵盖300多篇文献,探讨了视频生成、编辑与理解的研究进展与挑战,并提出了未来的研究方向,如数据集构建、物理真实性和长视频生成等。
SkyReels-A1是一种新的视频扩散模型,能够将静态肖像照片转化为自然的面部动画。该模型采用变换器架构和运动控制技术,生成高质量且保留身份特征的动态视频。
多伦多大学、Snap和UCLA团队推出的Wonderland模型能够从单张图像生成高质量的3D场景,并控制摄像轨迹。该技术结合了视频扩散模型和3D重建模型,显著提升了生成效率和视觉质量,适用于建筑设计和虚拟现实等领域。
本研究提出了一种新的视频扩散模型压缩方法,通过去除冗余浅层区块,提升推理速度,同时保持生成视频的质量和一致性。实验结果表明,该方法显著加快了文本和图像生成视频的推理时间。
本研究提出了一种新方法,通过潜在物理现象知识训练视频扩散模型,解决了现有模型在捕捉物理知识方面的不足,展现出显著的实际应用潜力。
该研究提出了一种名为DreamVideo的视频扩散模型,能够生成个性化视频。通过运动定制框架,结合时序信息和高分辨率数据,显著提升了视频生成的质量和控制能力。实验结果表明,该方法在多个数据集上表现优异,解决了传统方法在动态概念组合和运动生成上的不足。
本研究提出了一种名为视频指南的新框架,旨在解决文本到视频生成中的时序一致性问题。该方法利用预训练的视频扩散模型作为引导,显著提高了视频生成的时序质量和图像保真度,具有良好的成本效益和应用潜力。
本文介绍了多种3D生成方法,如DreamCraft3D、StereoDiffusion和DepthCrafter,利用深度估计和视频扩散模型生成高质量的3D对象和立体视频。这些方法克服了现有技术在一致性和细节上的不足,展现出强大的生成能力和广泛的应用潜力。
本研究提出了一种新的视频扩散模型,通过单眼深度估计控制视频的结构和内容保真度,实现高分辨率的文本到视频生成。用户可以独立指定对象运动和相机移动,提升视频质量和一致性。实验结果表明,该方法在视频深度估计和多目标合成方面表现优越,具有广泛的应用潜力。
该研究扩展了视频扩散模型,利用语义解剖信息生成超声心动图视频,提升了合成视频的真实感和连贯性。提出的去噪扩散概率模型(DDPMs)在医学影像分析中表现优异,Dice分数显著提高。HeartBeat框架实现了高保真度的超声视频合成,适用于多种医学成像任务。同时,研究建立了CardiacUDA数据集,改进了心脏结构分割效果。
本文提出了一种名为CamTrol的方法,实现了对视频扩散模型的摄像机运动控制,无需训练或微调。该方法通过重排噪点像素生成可控摄像机运动的视频,表现出色,具有鲁棒性和高质量的生成效果。实验结果显示,CamTrol在动态内容生成和三维旋转视频方面表现优异。
完成下面两步后,将自动完成登录并继续当前操作。