本研究提出了一种多上下文时序一致模块(MTCM),旨在解决视频目标分割中的查询不一致和上下文不足问题。该方法通过对齐查询和增强多上下文,显著提高了分割质量,在MeViS数据集上达到了47.6的J分数。
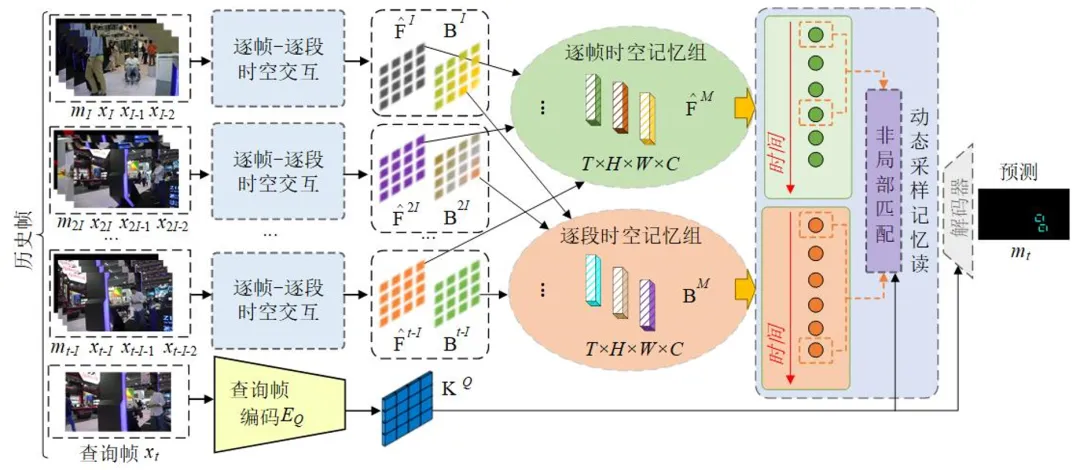
视频目标分割(VOS)旨在自动分割视频中的目标,广泛应用于多个领域。现有方法在复杂场景中面临挑战。本文提出逐帧和逐段时空交互记忆网络(FSSTIM),通过整合多粒度时空信息,提升分割准确性和效率,尤其在处理遮挡和相似目标时表现优异。实验结果表明,FSSTIM在多个数据集上超越现有方法,具有重要应用价值。
LiVOS是一种轻量级视频目标分割方法,旨在解决现有半监督视频目标分割在长视频和高分辨率下的内存限制问题。通过线性匹配和门控线性匹配,LiVOS在保持竞争性能的同时,GPU内存消耗减少了53%,支持高达4096p的推理。
本文介绍了一种基于语言描述的视频目标分割方法,利用扩展的语言基础模型实现时空连续预测。研究表明,该方法在多个数据集上优于传统技术,特别是在动态对象捕捉和跨模态学习方面。新提出的模型OnlineRefer和VD-IT在准确性和效率上均优于现有方法,推动了视频理解任务的发展。
该研究提出了一系列基于Transformer和循环神经网络的视频目标分割模型,涵盖零样本学习、时间一致性和多模态处理等技术,显著提高了分割精度和速度,推动了视频理解任务的发展。
该研究提出了多种视频目标分割模型,包括基于循环神经网络和Transformer架构的方法,表现优异。新模型OnlineRefer和SAM 2通过创新的学习策略和数据集,显著提高了目标分割的准确性和效率,尤其在真实场景中表现出色。
本研究提出了一种基于预训练视觉-语言模型的视频目标分割方法,重点增强跨模态特征交互。通过运动表达引导,开发了MeViS数据集,并在PVUW挑战赛中取得优异成绩。研究分析了静态数据和帧采样的有效性,提出了半监督算法PReMVOS,解决了多对象分割的挑战,展示了在复杂场景中的强大鲁棒性和准确性。
本研究提出了一种基于语义嵌入的视频目标分割模型,有效解决了复杂场景中的对象遮挡和分割问题。该模型在PVUW Challenge中获得第一名,展现出强大的鲁棒性和准确性,整体得分达到86.1%。
本文介绍了多种基于神经网络的半监督视频目标分割技术,包括全卷积网络、Transformer模型和循环神经网络。这些方法通过结合外观学习、时间聚合和少量样本学习,显著提高了分割精度和效率,并在多个基准测试中表现优异。
完成下面两步后,将自动完成登录并继续当前操作。