
基于逐帧和逐段时空交互记忆网络的高效视频目标分割 | 党吉圣,郑慧诚,赖剑煌等
内容提要
视频目标分割(VOS)旨在自动分割视频中的目标,广泛应用于多个领域。现有方法在复杂场景中面临挑战。本文提出逐帧和逐段时空交互记忆网络(FSSTIM),通过整合多粒度时空信息,提升分割准确性和效率,尤其在处理遮挡和相似目标时表现优异。实验结果表明,FSSTIM在多个数据集上超越现有方法,具有重要应用价值。
关键要点
-
视频目标分割(VOS)旨在自动分割视频中的目标,广泛应用于视频编辑、机器人导航、自动驾驶等领域。
-
现有方法在处理复杂视频场景时面临挑战,如目标遮挡、相似目标混淆和动态背景干扰,影响分割精度和效率。
-
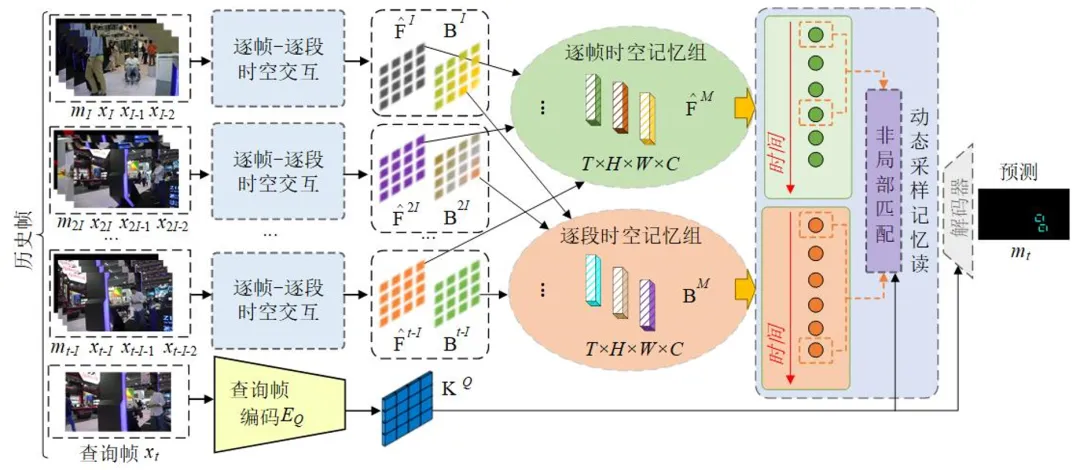
本文提出逐帧和逐段时空交互记忆网络(FSSTIM),整合多粒度时空信息,提升分割准确性和鲁棒性。
-
FSSTIM引入时空上下文图网络,增强逐帧和逐段记忆特征图的交互,提升对目标遮挡和相似目标的处理能力。
-
动态采样记忆读取策略结合不同粒度的采样窗口,高效提取关键历史信息,减少计算冗余,提升推理速度。
-
FSSTIM作为即插即用模块,可集成到现有VOS方法中,提升性能和泛化能力。
-
实验结果显示,FSSTIM在多个数据集上超越现有方法,尤其在复杂场景中表现优异,保持实时推理速度。
-
消融实验表明,FSSTIM的逐帧与逐段交互模块和动态采样策略在分割性能和效率上具有显著优势。
延伸解读
视频目标分割的应用前景
视频目标分割技术在视频编辑、机器人导航和自动驾驶等领域具有广泛的应用潜力。随着技术的进步,FSSTIM方法的引入可能会推动这些领域的进一步发展,提升自动化水平和用户体验。
复杂场景下的挑战与解决方案
在复杂场景中,目标遮挡和相似目标混淆是视频目标分割的主要挑战。FSSTIM通过引入逐段时空记忆模块和动态采样策略,有效提升了对这些问题的处理能力,为未来的研究提供了新的思路。
实时推理与计算效率
FSSTIM在保持高分割精度的同时,确保了实时推理速度。这一特性使其在实际应用中更具竞争力,尤其是在需要快速响应的场景,如自动驾驶和实时监控。
延伸问答
视频目标分割(VOS)是什么?
视频目标分割(VOS)是一项旨在自动分割视频中目标的核心任务,广泛应用于视频编辑、机器人导航和自动驾驶等领域。
现有的视频目标分割方法面临哪些挑战?
现有方法在复杂视频场景中面临目标遮挡、相似目标混淆和动态背景干扰等挑战,影响分割精度和效率。
FSSTIM网络的主要创新点是什么?
FSSTIM网络的主要创新点包括引入逐段时空记忆模块和动态采样机制,显著提升了目标分割的鲁棒性和效率。
FSSTIM如何提升分割的准确性和效率?
FSSTIM通过整合多粒度时空信息和动态采样策略,增强了对目标遮挡和相似目标的处理能力,同时减少了计算冗余。
FSSTIM在实验中表现如何?
FSSTIM在多个数据集上表现优异,分割准确性超越现有方法,尤其在复杂场景中对遮挡和相似目标的处理能力突出。
FSSTIM可以如何应用于现有的VOS方法?
FSSTIM作为即插即用模块,可以轻松集成到现有VOS方法中,进一步提升其性能和泛化能力。
