本文提出了一种自监督学习方案,以提高无人机在无GPS环境中的自我运动估计能力。通过改进遮挡处理方法,显著提升了无人机在高速飞行和接近障碍物时的视觉识别准确性,增强了实际应用表现。
本研究提出MASSeg模型,解决复杂视频物体分割中的小物体识别、遮挡处理和动态场景建模问题,利用MOSE+数据集和数据增强策略显著提升模型性能。
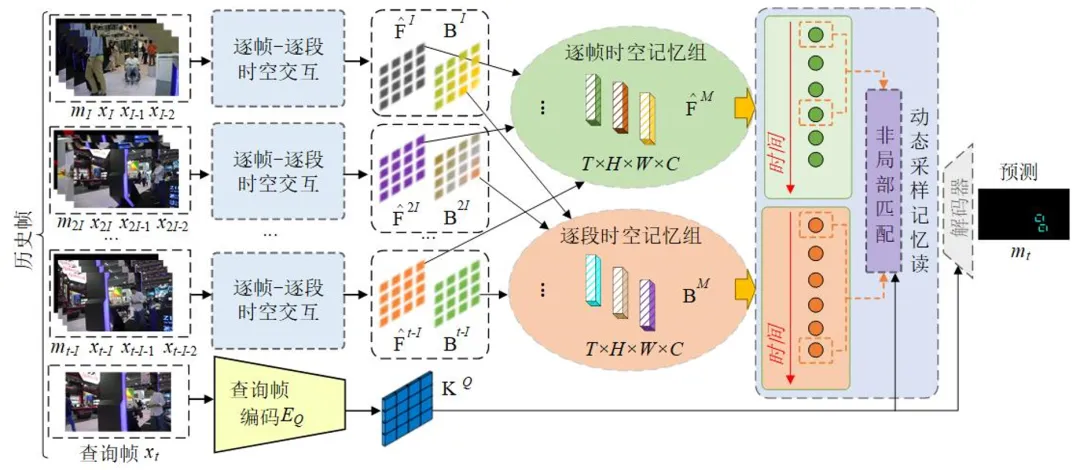
视频目标分割(VOS)旨在自动分割视频中的目标,广泛应用于多个领域。现有方法在复杂场景中面临挑战。本文提出逐帧和逐段时空交互记忆网络(FSSTIM),通过整合多粒度时空信息,提升分割准确性和效率,尤其在处理遮挡和相似目标时表现优异。实验结果表明,FSSTIM在多个数据集上超越现有方法,具有重要应用价值。
本研究提出了多种新颖的多目标跟踪方法,包括基于运动模型的跟踪器、贝叶斯框架和通用视角匹配框架,显著提升了跟踪性能,尤其在遮挡和非线性运动处理方面表现优越。实验结果显示,这些方法在多个基准数据集上取得了先进效果。
本文提出了一种名为Worldsheet的方法,利用单一RGB图像进行新视角综合。该方法通过可学习的中间深度生成逼真的3D视角,无需3D监督,并在多个数据集上超越现有技术,能够有效处理遮挡,生成可导航的3D弹出窗口。
本文介绍了一种基于无监督学习的多视图深度图像学习方法,强调多视图深度一致性以增强遮挡处理的鲁棒性。研究提出了GC-MVSNet和BlendedMVS等新方法和数据集,旨在提高深度预测的准确性和模型的泛化能力。实验结果表明,这些方法在多个基准数据集上表现优异。
本文介绍了多种基于 Transformer 的 3D 人体姿态估计方法,如 PostoMETRO、HMR、TokenPose 和 GTRS。这些方法通过优化模型结构和参数,提高了在单张图像中恢复人体网格的准确性,尤其在遮挡情况下表现优异。此外,PoseGPT 利用大型语言模型进行 3D 姿态理解和推理,开创了新的姿态分析方向。
完成下面两步后,将自动完成登录并继续当前操作。