

自适应并行推理:高效推理扩展的新范式
The Berkeley Artificial Intelligence Research Blog
·
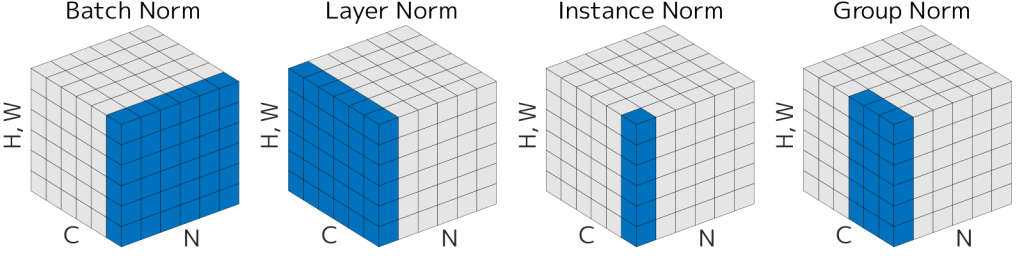
揭示批量归一化与层归一化
Louis Aeilot's Blog
·

批量归一化入门
MachineLearningMastery.com
·
GSPO:迈向持续拓展的语言模型强化学习
Blog on Qwen
·
