

PyTorch中的ImageNet
DEV Community
·

PyTorch中的Oxford-IIIT Pet
DEV Community
·

使用U-Net算法从卫星图像中识别陆地和水体
DEV Community
·

数据压缩语言模型(DataComp-LM):寻找下一代语言模型训练集
Apple Machine Learning Research
·
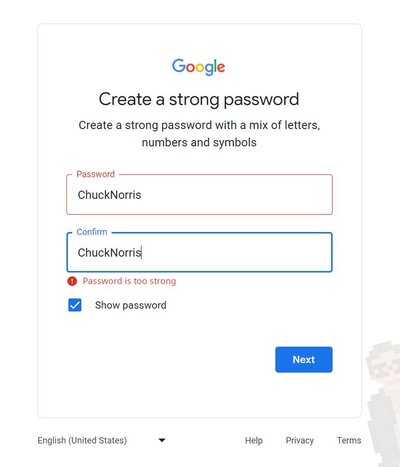
幽默:谷歌用户体验大概是世界上最差的
极道
·


