

基于评估指标的标签分布学习中的标注饱和度
Apple Machine Learning Research
·

大型语言模型评估与AI代理监控的可观测性
The JetBrains Blog
·
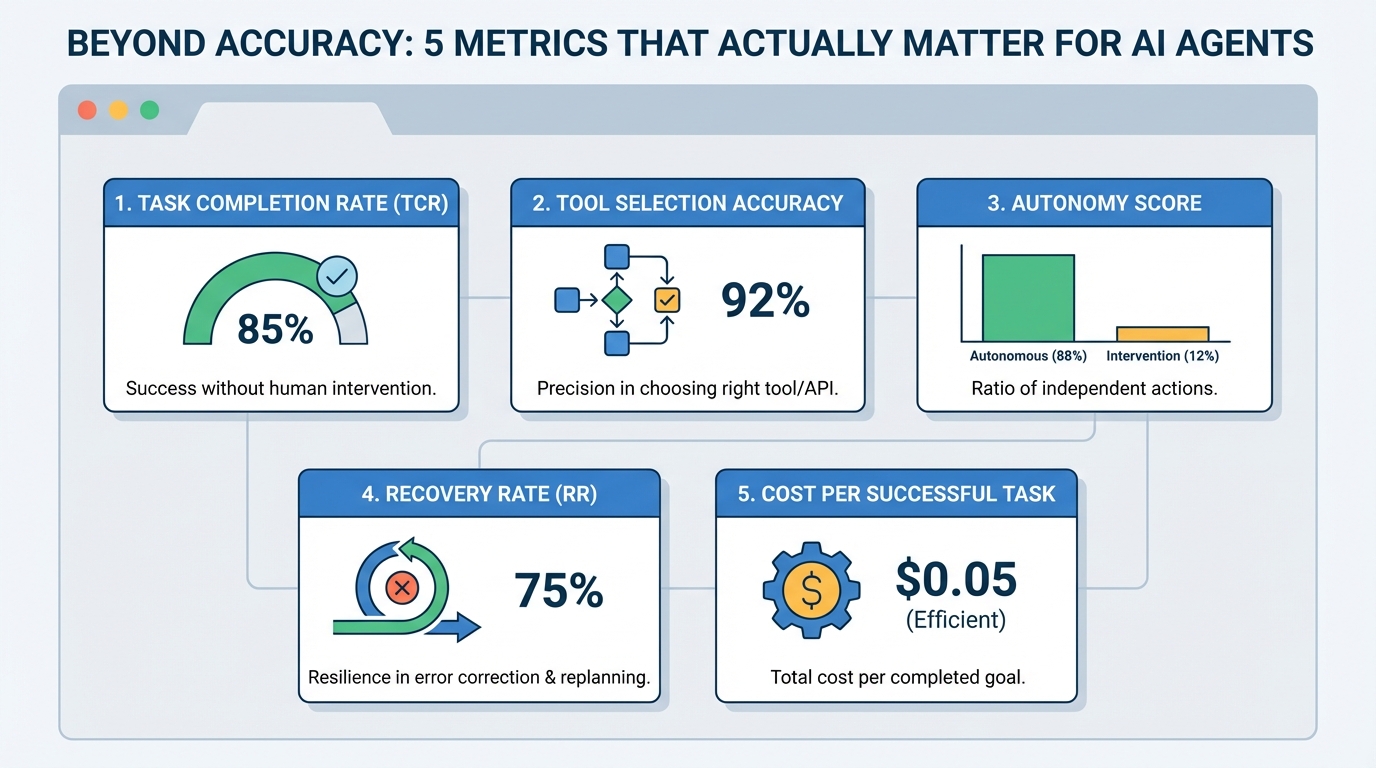
超越准确性:人工智能代理真正重要的五个指标
MachineLearningMastery.com
·

为什么大多数人错误使用SMOTE,以及如何正确使用它
KDnuggets
·

评估基于 LLM 的语音助手:超越传统指标的指南
实时互动网
·

评估评估指标——幻觉检测的幻影
Apple Machine Learning Research
·
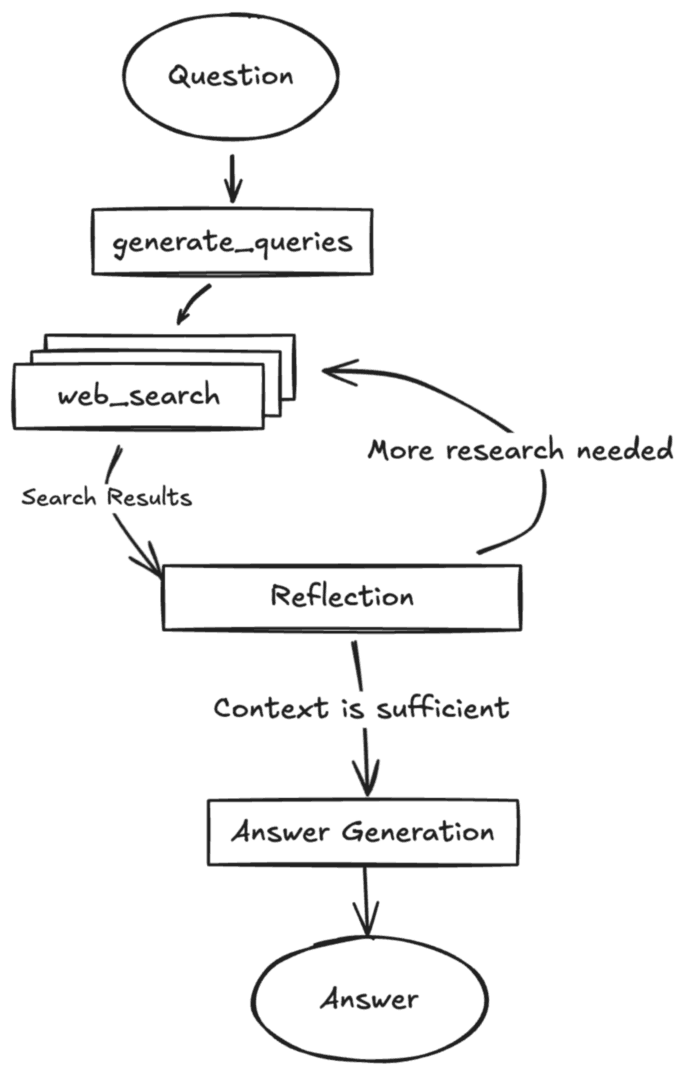
RAG 简要回顾
Measure Zero
·

模型选择对决:选择最佳模型的六个考虑因素
MachineLearningMastery.com
·

用于AI系统性能评估的大型语言模型框架
DEV Community
·

自然语言处理评估指标
DEV Community
·
大型语言模型是否有英语口音?评估和改善多语言大型语言模型的自然性
Apple Machine Learning Research
·

