
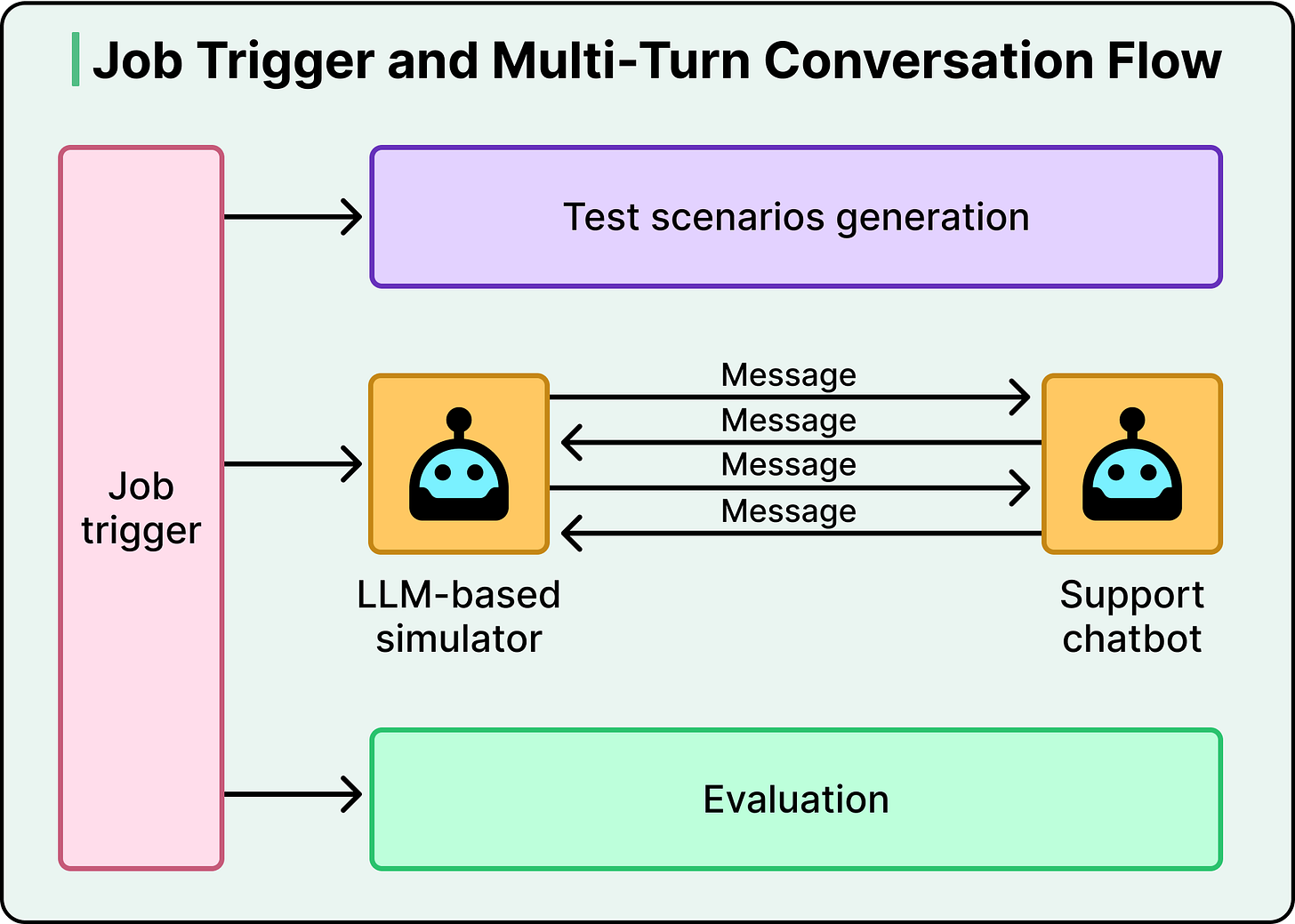
DoorDash如何构建评估大型语言模型的测试系统
ByteByteGo Newsletter
·

我如何编程?(2025年11月版)
Xuanwo's Blog
·

通过定制评估者实现从试点到生产的转变
Databricks
·

播客:如果无法测试,就不要部署:人工智能开发的新规则?
InfoQ
·


AlphaWrite:通过进化提升AI叙事
InfoQ
·

将大型语言模型作为评判者与人类偏好对齐
LangChain Blog
·

