

为长时间运行的代理构建上下文修剪管道
MachineLearningMastery.com
·
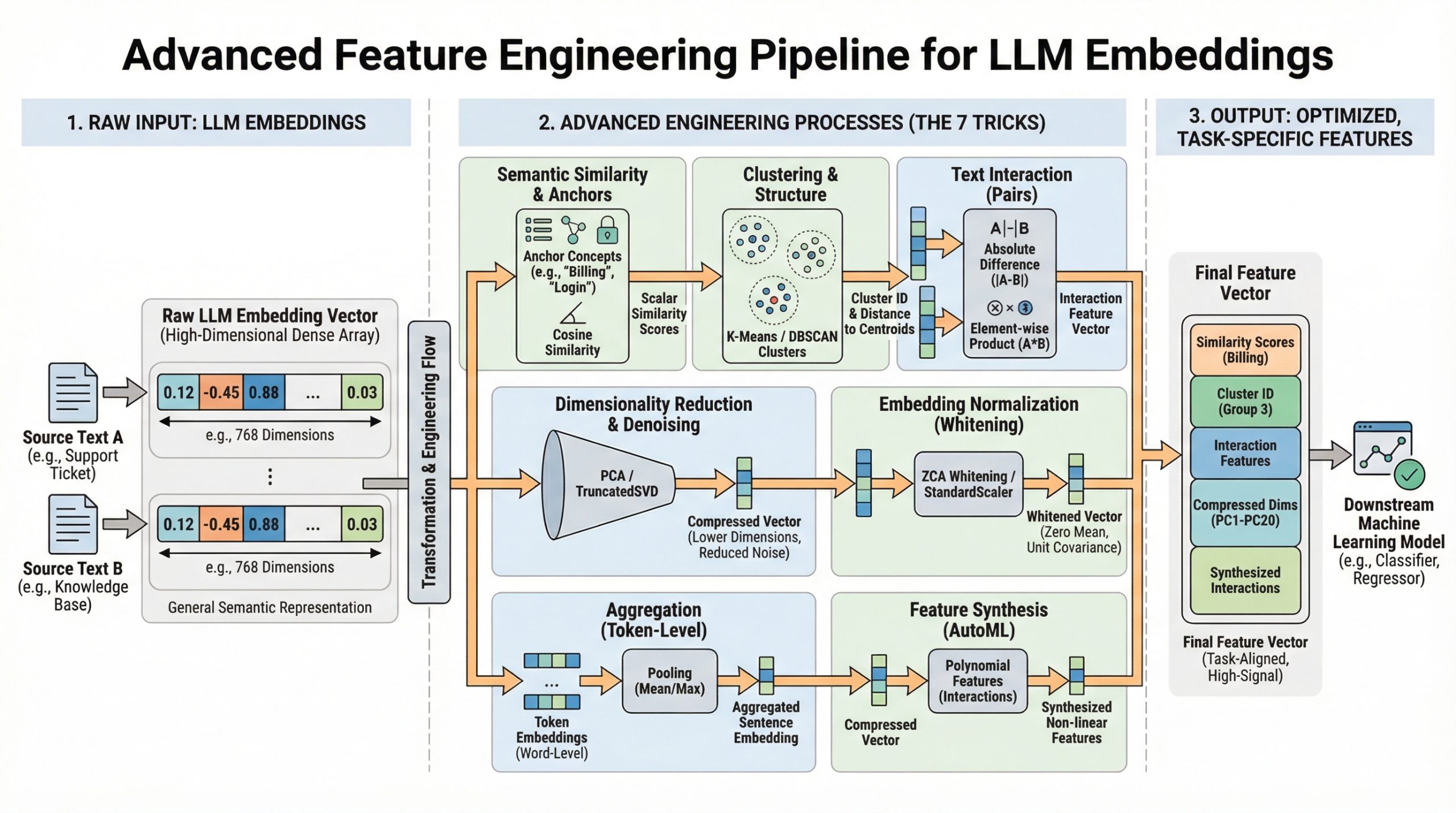
7种利用大型语言模型(LLM)嵌入进行高级特征工程的技巧
MachineLearningMastery.com
·

本地Atlas和Ollama的MongoDB向量搜索索引
DEV Community
·

个人知识管理中的语义相似性
DEV Community
·

教程:我们如何在PostgreSQL中直接构建反向视频搜索系统
DEV Community
·

通过代理混合检索提升您的RAG应用
The New Stack
·

向量嵌入详解:强大AI的初学者指南
The New Stack
·
