
7种利用大型语言模型(LLM)嵌入进行高级特征工程的技巧
内容提要
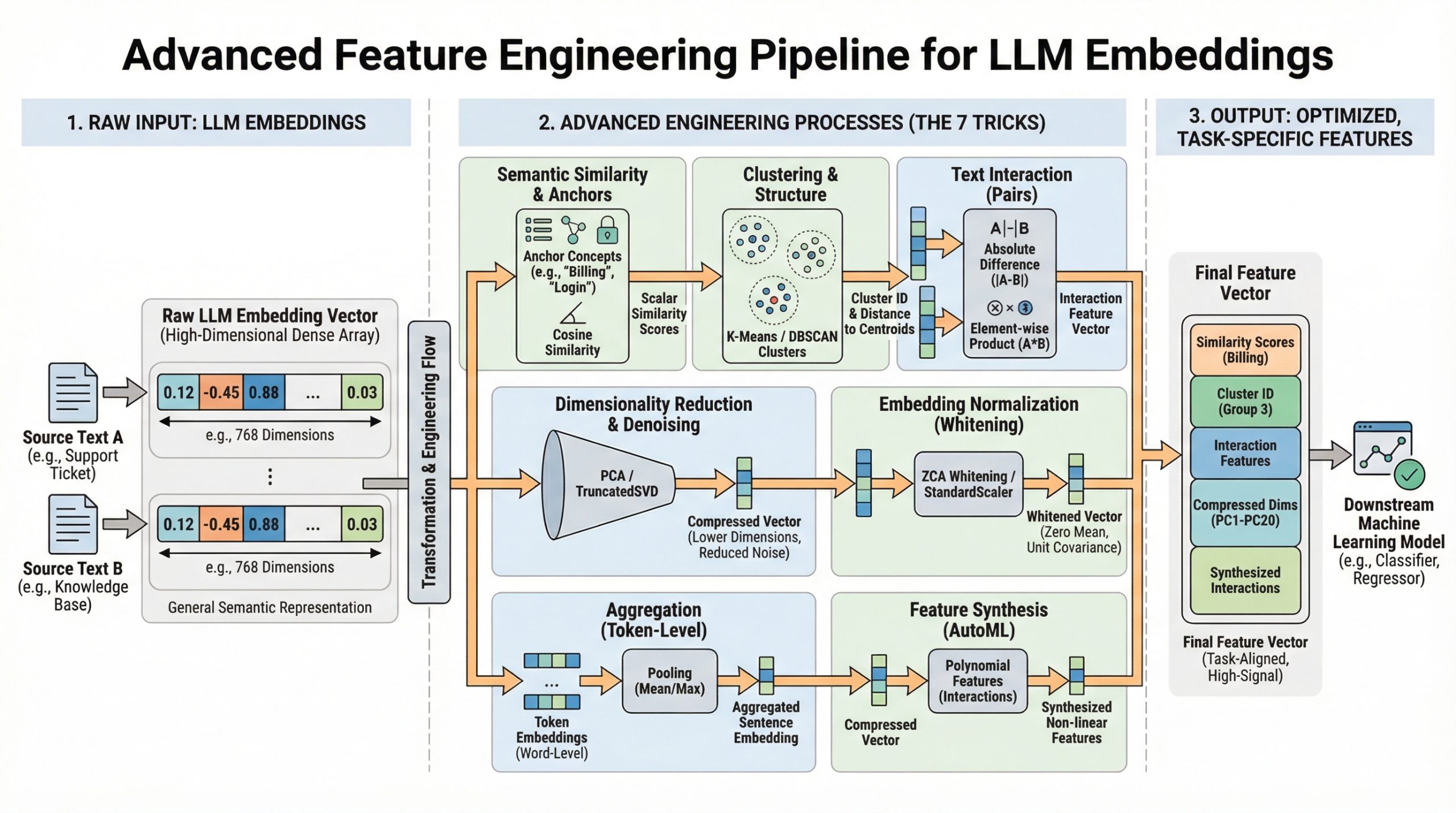
本文介绍了七种利用大型语言模型(LLM)嵌入进行高级特征工程的技巧,包括计算语义相似性、降维和去噪、使用聚类标签和距离、文本差异嵌入、嵌入白化、句子与词级嵌入聚合,以及将嵌入作为特征合成的输入。这些方法可以将通用嵌入转化为特定任务的高信号特征,从而提升模型性能。
关键要点
-
本文介绍了七种利用大型语言模型(LLM)嵌入进行高级特征工程的技巧。
-
第一种技巧是计算语义相似性,通过与关键概念嵌入的余弦相似度来生成可解释的特征。
-
第二种技巧是降维和去噪,使用PCA等方法减少嵌入的维度以去除噪声并提高模型性能。
-
第三种技巧是使用聚类标签和距离作为特征,通过无监督聚类发现自然主题组并将其作为新特征。
-
第四种技巧是文本差异嵌入,通过计算文本对之间的差异和元素乘积来捕捉它们的关系。
-
第五种技巧是嵌入白化,通过ZCA白化来改善相似性和检索任务的性能。
-
第六种技巧是句子与词级嵌入聚合,使用词级嵌入的聚合来捕捉长文档中的细粒度信息。
-
第七种技巧是将嵌入作为特征合成的输入,利用自动化特征工程工具发现复杂的非线性交互。
延伸解读
语义相似性的重要性
在特征工程中,计算语义相似性可以帮助模型更好地理解文本内容。通过与关键概念的嵌入进行余弦相似度计算,模型能够生成可解释的特征,这对于分类任务尤为重要。选择合适的锚点是关键,锚点可以基于领域知识或通过聚类获得。
降维与去噪的必要性
LLM嵌入通常是高维的,降维不仅可以去除噪声,还能降低计算成本。使用PCA等方法可以有效提取重要特征,避免维度灾难对模型性能的影响。然而,降维是有损的,因此需要在降维后验证特征是否保持或提升了模型性能。
聚类标签的应用
通过对嵌入进行无监督聚类,可以发现数据中的自然主题组。使用聚类标签和距离作为新特征,可以为模型提供结构性知识,帮助提高分类或异常检测的效果。选择合适的聚类数量是成功的关键,建议使用肘部法则或领域知识来确定。
嵌入白化的优势
嵌入白化可以改善相似性和检索任务的性能,通过将嵌入的均值调整为零并使协方差为单位,可以避免某些高方差方向主导相似性计算。这一过程在现代语义搜索中非常常见,确保了不同维度的重要性均衡。
延伸问答
如何利用大型语言模型计算语义相似性?
通过计算嵌入与关键概念嵌入的余弦相似度,可以生成可解释的特征。
降维和去噪在特征工程中有什么作用?
降维可以去除噪声、降低计算成本,并揭示更准确的模式。
如何使用聚类标签和距离作为特征?
通过无监督聚类发现自然主题组,并将聚类分配和距离作为新特征。
文本差异嵌入的应用场景是什么?
文本差异嵌入适用于需要比较文本对的任务,如重复问题检测和语义搜索相关性。
什么是嵌入白化,为什么要使用它?
嵌入白化是通过ZCA白化来改善相似性和检索任务的性能,确保所有维度的重要性均等。
如何将句子级和词级嵌入聚合?
通过聚合词级嵌入,可以捕捉长文档中的细粒度信息,避免单一句子嵌入丢失重要信息。
