OpenAI与Anthropic合作进行模型安全性评估,结果显示Claude 4模型在遵循指令方面表现良好,但在抵抗越狱攻击上不及OpenAI的模型。Claude模型在幻觉评估中的拒绝率高达70%,显示出其对不确定性的意识。两家实验室的合作将提升模型的安全性和对齐性,未来将继续改进评估方法。
本文介绍了MASTERKEY框架,旨在自动化大语言模型聊天机器人的越狱攻击。研究揭示了现有防御机制的不足,并通过时间敏感性分析和强化学习生成有效的越狱提示,显著提高了多平台的越狱成功率,强调了AI安全与伦理的重要性。
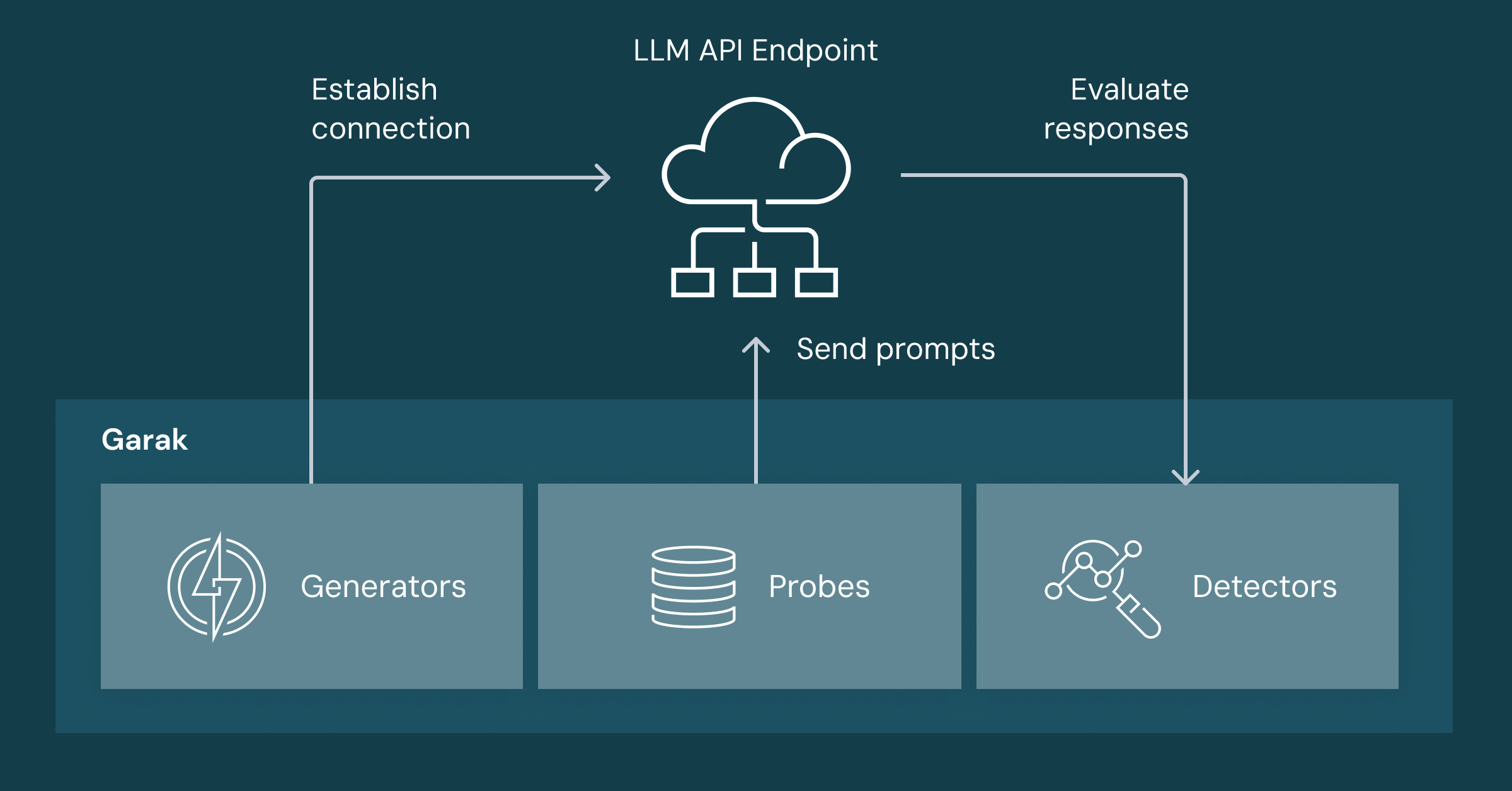
大型语言模型(LLMs)在现代工作流程中扮演着重要角色,但其广泛应用也带来了安全挑战,如越狱攻击和间接提示注入攻击。为评估LLM的安全性,NVIDIA推出了开源工具Garak,以检测模型脆弱性并确保安全部署。
本研究创建了AJailBench,评估大型音频语言模型(LAMs)在越狱攻击下的安全性。结果表明,现有LAM在面对精心设计的音频攻击时存在明显脆弱性,强调了开发更强大防御机制的必要性。
本研究聚焦于大语言模型的越狱攻击,提出了ICE新方法,解决了查询次数多和跨模型泛化差的问题。通过开发BiSceneEval评估数据集,实验结果表明ICE在有效性和可转移性上优于现有技术,揭示了防御机制的脆弱性。
本文探讨了大型音频语言模型的越狱攻击,指出现有文本攻击的不足,并提出了一种新方法AudioJailbreak,具有异步性、普遍性、隐蔽性和抗干扰性,能有效提升模型安全性。
本研究分析了大型语言模型(LLMs)在安全性方面的漏洞,特别是对越狱攻击的脆弱性。研究发现一种普遍的越狱攻击方法,能够绕过多个模型的安全控制,导致有害输出,提示行业需重视AI安全风险。
本研究提出了一种可解释的人工智能解决方案,针对大型语言模型的安全威胁,设计了XBreaking越狱攻击,通过目标噪声注入突破安全限制,强调了审查机制的重要性。
本研究评估了越狱攻击对大型语言模型的影响,发现越狱输出普遍降低了模型的效用,并提出了“越狱税”概念,强调了AI安全性的重要性。
本研究揭示了集成图像提示适配器的文本到图像扩散模型中存在一种新型越狱攻击——劫持攻击。该攻击通过上传不可察觉的对抗样本,劫持用户的图像生成服务。实验验证了攻击的可行性,并探讨了结合对抗训练模型的解决方案。
本研究探讨大型语言模型(LLMs)在自主响应中的价值一致性问题,并提出迭代提示技术以提高越狱攻击的有效性。研究发现,采用说服策略可显著提升攻击成功率,最高可达90%。
本研究提出了一种基于隐喻的越狱攻击方法MJA,旨在解决文本到图像模型的安全漏洞。MJA通过生成隐喻式对抗提示,提高了攻击效果和查询效率,实验结果显示其在多种模型上表现良好。
STShield是一种创新的单标记哨兵机制,旨在实时监测大型语言模型的越狱攻击。该方法通过在模型响应中附加安全指示符,利用模型的对齐能力进行检测。研究表明,STShield在保持模型实用性的同时,有效防御多种越狱攻击,具备优越的防御性能和较低的计算开销,适合实际部署。
本研究评估了小型语言模型(SLMs)在越狱攻击下的脆弱性,发现47.6%的SLMs对攻击高度敏感,38.1%无法抵御有害查询。模型的大小、架构和训练技术对安全性有显著影响,强调了安全设计的重要性。
本研究评估了13种小型语言模型在越狱攻击下的安全性,发现大多数模型易受攻击且对有害提示脆弱。同时,分析了多种防御方法的有效性,为提升小型语言模型的安全性提供了见解。
本研究探讨大型语言模型(LLMs)安全机制的脆弱性,认为模板锚定是其易受攻击的关键因素。通过将安全机制与模板区域分离,可以有效降低模型对越狱攻击的脆弱性。
本研究提出DELMAN方法,旨在解决大型语言模型在决策应用中的越狱攻击问题。该方法通过调整少量参数实现动态防护,同时保持模型性能,实验结果表明其有效应对新攻击实例。
AIxiv专栏报道了香港科技大学等机构提出的SelfDefend框架,旨在提高大语言模型的安全性,抵御越狱攻击。该框架通过引入影子模型,显著降低攻击成功率,同时保持低延迟,展示了AI系统自我保护的潜力。
研究人员开发了“宪法分类器”,有效防止AI模型遭受通用越狱攻击。该系统通过合成数据训练,将越狱成功率从86%降低至4.4%。尽管保护显著,但仍需额外防御措施应对新技术。
DeepSeek AI在安全审计中发现严重的越狱攻击漏洞,攻击者可通过缓冲区溢出控制其功能,可能导致错误信息传播和基础设施损害。开发者需加强安全措施,确保AI系统安全。
完成下面两步后,将自动完成登录并继续当前操作。