Unicode 17.0于2025年发布,新增4803个字符,包括代表非二元性别的汉字「㐅也」和男性代词「男也」,反映了语言演变与性别意识的提升。
本研究提出了FairTranslate数据集,以评估机器翻译中的性别偏见,特别关注非二元性别。通过2418对英法句子,揭示了主流语言模型在性别代表性方面的偏差,强调了确保翻译系统公平与包容性的必要性。
本研究探讨了语言模型对边缘化群体的偏见,填补了特定国家和地区的研究空白。结果显示,23个语言模型对来自埃及、阿拉伯国家、德国、英国和美国的270个边缘化群体普遍存在偏见,尤其是针对非二元性别、LGBTQIA+和黑人女性的交叉偏见更为明显。
本研究探讨大型语言模型中的性别多样性偏见,特别是对跨性别和非二元性别身份的影响。评估发现,经过对齐的模型在某些阶段可能加剧现实中的性别伤害。建议采用社区知情的偏见评估框架,以更有效识别和应对这些问题。
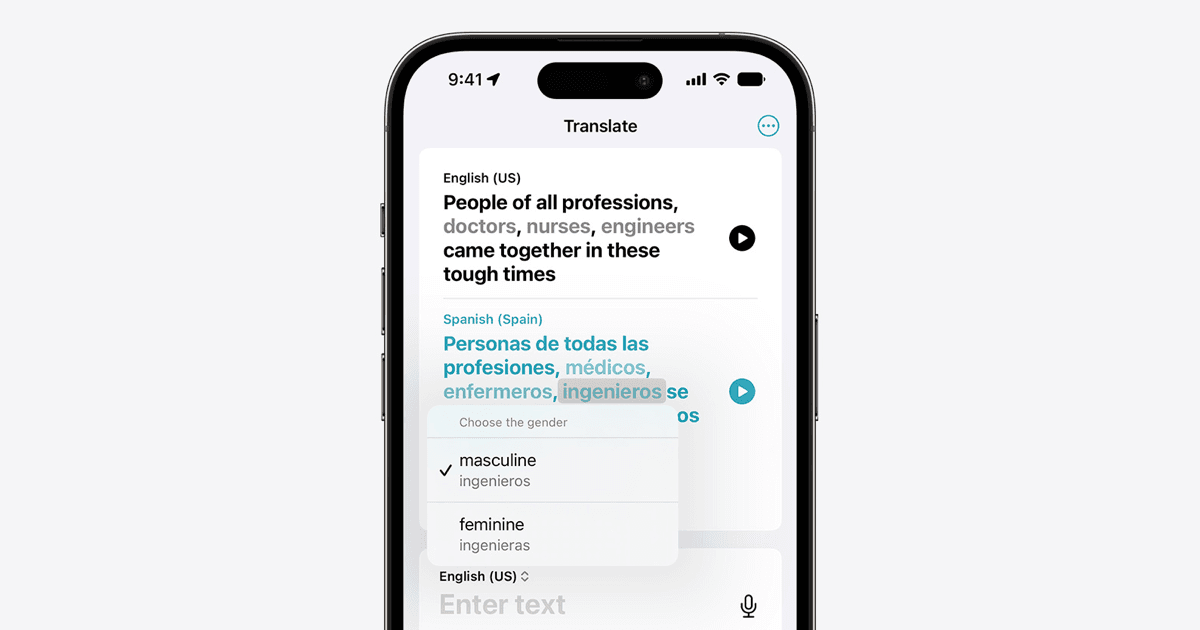
机器翻译在处理语法性别时遇到挑战。某些语言需要性别明确的词汇,而其他语言则是中性的。研究者开发了一种方法,让用户在翻译时选择合适的性别形式,无需额外计算负担。该方法已应用于苹果翻译应用,支持从英语到西班牙语、法语和葡萄牙语。研究还发布了数据集,推动领域发展。未来挑战包括扩展语言对和处理非二元性别。
完成下面两步后,将自动完成登录并继续当前操作。