

TiC-LM:一个用于时间连续大型语言模型预训练的网络规模基准
Apple Machine Learning Research
·

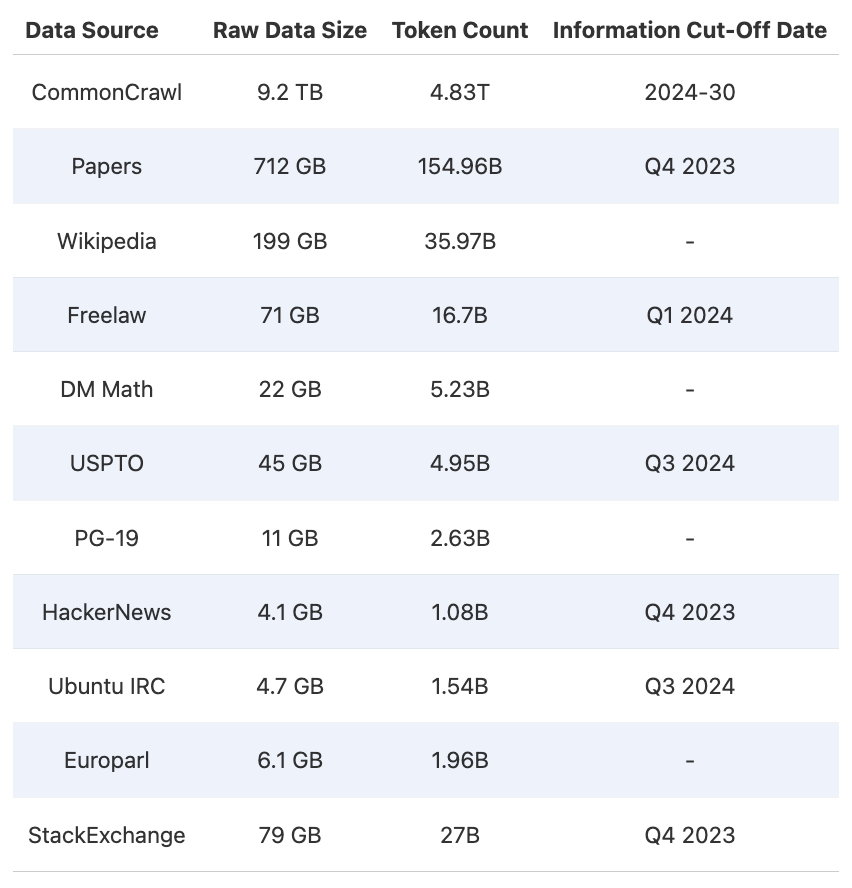
最大的顶级数据集开源,HuggingFace排名第一,可创建15万亿Token
OneFlow深度学习框架
·
通过准确度预测器修剪大型语言模型
BriefGPT - AI 论文速递
·
