
最大的顶级数据集开源,HuggingFace排名第一,可创建15万亿Token
内容提要
LLM360是Petuum与MBZUAI联合推出的开源大型语言模型项目,旨在提升开源代码的透明度。该项目发布了13个开源模型和一个名为TxT360的预训练数据集,包含超过15万亿个token,提供高质量、多样化的数据,帮助开发者更高效地创建大型语言模型。TxT360在Hugging Face上排名第一,具备丰富的元数据和详细的处理步骤,为LLM开发者提供了重要资源。
关键要点
-
LLM360是Petuum与MBZUAI联合推出的开源大型语言模型项目,旨在提高开源代码的透明度。
-
该项目发布了13个开源模型,涵盖多个大型语言模型系列,并提供模型检查点、代码和数据。
-
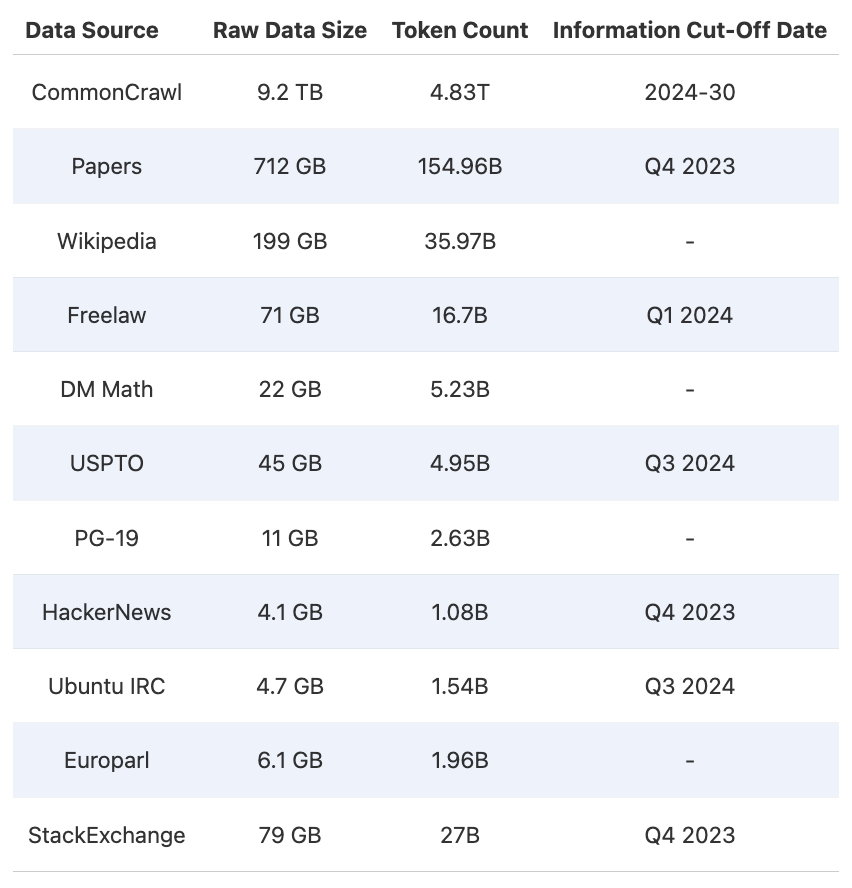
TxT360是一个完全清理过的预训练数据集,包含超过15万亿个token,提供高质量、多样化的数据。
-
TxT360在Hugging Face上排名第一,击败了22万个数据集,专注于干净的数据和精确的控制。
-
LLM360设计了一条全面的数据处理流水线,以创建集成、去重和清理的数据集,结合了开发者常用的数据源。
-
TxT360中存储了丰富的元数据,使预训练者能够更精确地控制数据分布,探索更先进的加权技术。
-
该项目记录了所有详细的步骤、决策理由和分析结果,为LLM开发者提供了宝贵的资源。
延伸解读
开源项目的透明度与民主化
LLM360项目的推出不仅提升了开源代码的透明度,还为AI研究的民主化奠定了基础。通过公开训练过程和最佳实践,开发者能够更轻松地参与到大型语言模型的开发中,推动技术的普及与创新。
TxT360数据集的优势
TxT360数据集以其超过15万亿个token的规模和高质量的数据源,成为LLM开发者的重要资源。其独特的去重和清理流程,确保了数据的干净与多样性,为模型训练提供了更可靠的基础。
数据处理流水线的创新
LLM360设计的全面数据处理流水线,解决了开发者在数据集组合和清理中的技术挑战。这一创新不仅节省了时间,还提高了数据集的质量,为大型语言模型的训练提供了更高效的解决方案。
延伸问答
LLM360项目的主要目标是什么?
LLM360项目旨在提高开源代码的透明度,帮助开发者更轻松地创建开源大型语言模型。
TxT360数据集的特点是什么?
TxT360是一个包含超过15万亿个token的预训练数据集,专注于干净的数据和精确的控制,提供高质量和多样化的数据。
TxT360在Hugging Face上的表现如何?
TxT360在Hugging Face上排名第一,击败了22万个数据集,成为最受欢迎的预训练数据集。
LLM360如何处理数据以创建TxT360?
LLM360设计了一条全面的数据处理流水线,通过合并和去重多个数据源,创建了清理过的TxT360数据集。
TxT360数据集对LLM开发者有什么帮助?
TxT360为LLM开发者提供了丰富的元数据和详细的处理步骤,帮助他们更精确地控制数据分布。
LLM360项目发布了多少个开源模型?
LLM360项目已发布了13个开源模型,涵盖多个大型语言模型系列。
