华为推出Pangu Ultra MoE训练系统,采用国产技术实现高效训练,支持超大规模模型。该系统每2秒处理一道高数题,显著提升训练效率和算力利用率,突破多项技术瓶颈。
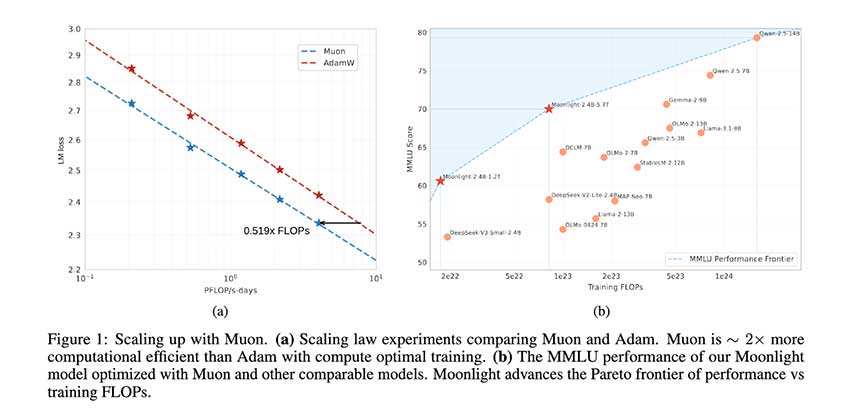
Muon优化器通过权重衰减和一致的RMS更新,提高了大规模语言模型的稳定性和效率,降低了计算成本。Moonlight模型表现优异,超越同类,支持多语言处理,推动高效训练方法的探索。
最新研究表明,在强化学习中,数据的质量比数量更为重要。通过学习影响力度量(LIM),研究者发现精选的1,389个样本的效果超过了8,523个样本,强调了高质量样本对模型学习的重要性。这一发现挑战了传统观念,为高效训练提供了新方法。
本文综述了视觉语言模型在资源受限的边缘设备上的应用挑战,重点讨论模型压缩和高效训练方法,提出了优化策略,并展示了其在医疗、环境监测和自主系统中的应用潜力。
清华大学TSAIL团队提出的免引导采样算法GFT,在视觉生成模型中实现高效训练,性能与CFG相当,且采样成本减半。GFT通过简单代码修改即可应用于多种视觉模型,显著提升生成质量与多样性。
本文介绍了一种新型隐私保护方法,结合联邦学习与数据草图,使大型语言模型在不共享个人数据的情况下高效训练。该方法降低了通信成本,支持设备微调,性能与集中训练相当。
本文研究了神经网络的收敛学习现象,发现不同特征的学习效果存在差异,并提出了多种相似性度量方法。研究还探讨了高效的训练策略,结果表明预训练网络中的神经元存在冗余,通过优化特征合并可以提高任务效率。
本文介绍了超小型语言模型(STLMs)的创新技术,包括字节级分词、参数联系和高效训练策略,使参数减少90%-95%。研究表明,小型模型在准确性和运行时间上优于大型模型,并探讨了预训练效果、模型架构整合及评估方法,以提升语言模型的可访问性和实用性。
本文介绍了多种高效训练对比语言-图像预训练(CLIP)模型的方法,包括RECLIP、DeCLIP和MobileCLIP。这些方法通过优化数据利用和计算资源,提高了模型的性能和训练效率。研究表明,使用高质量数据和合适的训练策略可以显著提升CLIP的准确性和泛化能力,为实际应用提供经济可行的解决方案。
CatBoost是一种灵活有效的机器学习技术,特别适用于处理分类特征的数据集。它使用目标编码和有序增强等先进技术,能够独立处理分类数据并进行高效训练。CatBoost具有许多优点,包括支持分类特征、高质量结果、梯度提升、高效性、GPU加速、减少过拟合、处理丢失数据和快速预测等。它在推荐系统、欺诈检测、文本和图像分类、客户流失预测、医疗状况、NLP和时间序列预测等领域有广泛应用。CatBoost是一种强大的机器学习工具,能够处理分类数据、减少过拟合、做出准确预测并提供模型的可解释性和可扩展性。
本研究提出了一种名为SparseProp的新颖的基于事件的算法,用于模拟和训练稀疏的脉冲神经网络,并通过每个网络脉冲将前向传递和反向传递的计算复杂度从O(N)降低到O(log(N)),实现了大规模脉冲网络的准确模拟和高效训练。
该研究使用RNS开发了一种基于方法的模拟加速器,可以在只使用6位精度的数据转换器的情况下,实现优于FP32精度的99%以上的DNN推断和高效训练。提出了一种容错数据流,利用冗余RNS纠错码保护计算,以应对模拟加速器中的噪声和误差。
完成下面两步后,将自动完成登录并继续当前操作。