
Moonshot AI 推出 Muon 和 Moonlight:利用高效训练技术优化大规模语言模型
内容提要
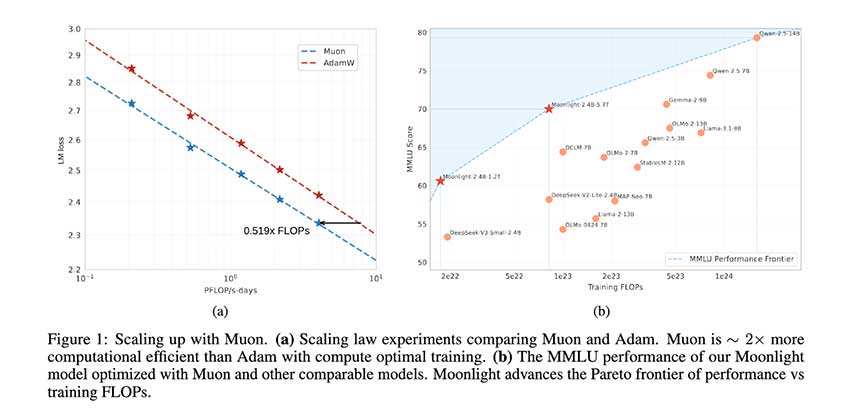
Muon优化器通过权重衰减和一致的RMS更新,提高了大规模语言模型的稳定性和效率,降低了计算成本。Moonlight模型表现优异,超越同类,支持多语言处理,推动高效训练方法的探索。
关键要点
-
优化大规模语言模型需要先进的训练技术,以降低计算成本并保持高性能。
-
现有优化器如AdamW需要细致的超参数调整和大量计算资源,效率低下。
-
Muon优化器通过权重衰减和一致的RMS更新,提高了训练稳定性和效率。
-
Moonlight模型使用5.7万亿个token进行训练,表现优异,超越同类模型。
-
Moonlight在多个基准测试中表现出色,尤其在多语言处理任务中取得优异成绩。
-
Muon的创新解决了训练大型模型的可扩展性挑战,降低了训练成本。
-
Muon和Moonlight的开源促进了对大规模模型高效训练方法的探索。
延伸解读
优化器的演变与挑战
在大规模语言模型的训练中,优化器的选择至关重要。传统的优化器如AdamW虽然广泛使用,但在处理大规模模型时效率低下,需频繁调整超参数。Muon优化器的推出,旨在解决这些问题,通过权重衰减和一致的RMS更新,提升了训练的稳定性和效率,降低了计算需求。
Moonlight模型的多语言优势
Moonlight模型在多语言处理任务中表现出色,尤其在中文任务上取得了优异成绩。这表明其在处理不同语言时的强大泛化能力,适应性强,能够满足全球用户的需求。随着多语言应用的增加,Moonlight的优势将为其在市场中的竞争力提供支持。
开源的意义与未来探索
Muon和Moonlight的开源不仅促进了研究界对高效训练方法的探索,也为开发者提供了便捷的工具。这种开放性将加速技术的迭代与创新,推动大规模模型的进一步发展。未来,研究者可以在此基础上进行更多实验,探索更高效的训练策略。
延伸问答
Muon优化器的主要优势是什么?
Muon优化器通过权重衰减和一致的RMS更新,提高了训练稳定性和效率,降低了计算成本。
Moonlight模型在多语言处理方面的表现如何?
Moonlight模型在多语言处理任务中表现优异,尤其在多个基准测试中取得了高分。
为什么现有的优化器在大规模训练中效率低下?
现有优化器如AdamW需要细致的超参数调整和大量计算资源,随着模型规模的扩大,其效果逐渐减弱。
Muon和Moonlight的开源对研究界有什么影响?
Muon和Moonlight的开源促进了对大规模模型高效训练方法的探索,支持了研究界的进一步研究。
Moonlight模型使用了多少个token进行训练?
Moonlight模型使用了5.7万亿个token进行训练。
Muon优化器如何解决训练大型模型的可扩展性挑战?
Muon通过结合权重衰减和一致的RMS更新,提高了稳定性和效率,从而解决了可扩展性挑战。
