Blip官网推出跨平台无线传输App AirClap,用户对AirDrop功能的使用难度表示不满。iOS 16.1.1更新后,国行iPhone的AirDrop功能有所调整。
本文介绍了图像生成技术的发展,重点讨论了CLIP和BLIP及其变体的结构与训练方法。CLIP通过对比学习实现图像与文本的匹配,BLIP结合理解与生成能力,提升多模态任务表现。BLIP2引入Q-Former模块,优化视觉与语言对齐,InstructBLIP增强指令遵循能力,适应不同任务需求。
本研究针对解读CTPA扫描和生成准确放射科报告的复杂性,提出了Abn-BLIP模型。该模型采用可学习查询和跨模态注意机制,显著提高了异常检测和报告生成的准确性和全面性,超越了现有的医疗视觉语言模型,展示了多模态学习策略在改善放射科报告方面的潜力。
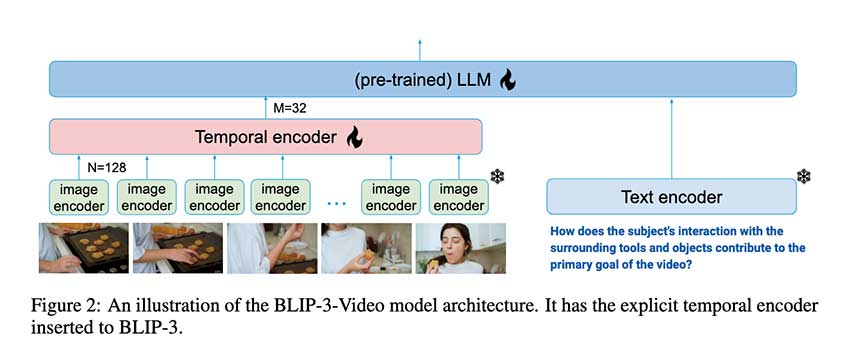
视觉语言模型(VLM)在视频理解中变得越来越重要,特别是BLIP-3-Video模型通过引入时间编码器显著提升了视频处理效率。该模型将视觉标记数量减少至16-32个,保持高准确率并降低计算开销,适用于复杂视频任务,推动了AI在各行业的应用。
本文介绍了VIOLET、E-ViLM和LongVLM等视频语言模型的研究进展。这些模型通过新技术和优化算法,在视频问答和文本到视频检索等任务中表现优异,显著提升了效率和性能。此外,研究提出了TemporalBench基准,以评估模型在时间理解方面的能力,揭示了当前模型与人类之间的差距。
本研究针对多模态大语言模型中知识更新的挑战,提出了一种新的检索增强框架RA-BLIP。通过引入自适应选择知识生成策略,本文实现了高效的信息提取和多模态知识的融合,显著提升了模型在开放多模态问答任务上的表现,超越了现有的检索增强模型。
本研究解决了大型多模态模型(LMMs)开发中数据集和训练方法不足的问题,并提出了一种新的框架xGen-MM(BLIP-3)。该框架通过严格评估和安全调优,展示了在多任务场景下的强大性能,并为未来研究提供了开放的资源和数据。
本文探讨了通过语言指导提升视觉问答模型性能的方法。研究表明,结合CLIP和BLIP模型与知识图谱能显著提高问答准确率。提出的多模态框架在多个数据集上表现优异,推动了视觉问答技术的发展。
本文介绍了多个深度学习和图像处理框架,包括基于JavaScript的矩阵库、TensorFlow.js、BLIP和ImageLab等。这些工具支持在浏览器中进行机器学习和图像处理,提升了性能和可用性。
本文介绍了多模态模型的基本思想、结构和训练数据集情况,并详细介绍了CLIP、BLIP和BLIP2等经典多模态模型。同时,介绍了飞桨多模态框架PaddleMIX和其在VQA和Caption任务中的应用。
本文探讨了利用预训练的视觉语言模型(VLMs)作为强化学习代理的奖励来源,提出了BLIP和VLM-CaR等新框架,显著提升了视觉与语言任务的性能。研究表明,VLMs在复杂任务中展现出强大的泛化能力和鲁棒性,有效支持强化学习策略的训练。
该研究提出了一种多模态双向Transformer模型,结合文本和图像编码器,显著提升了假新闻检测的准确率,达到了99.98%。同时,研究还优化了多模态生成模型,提高了图像与文本的理解和生成效果。
该研究提出了一种高效调优屏幕截图字幕任务的方法,通过冻结模型参数并仅训练相关权重,可以实现与整个模型微调相当的性能,同时大幅减少参数数量。研究还探讨了适配器在视觉语言模型中的应用。
clip_interrogator是一种多模态工具,结合CLIP和BLIP生成图片描述。用户可以安装和配置不同模型,使用多种模式(如best、fast、classic、negative)获取自然语言描述,并支持自定义词库,适用于多种应用场景。
Blip是一个新的MySQL监控工具,专为MySQL设计,具有插件架构,可适用于各种MySQL环境。Blip是最先进的MySQL监控工具,可以解决实际问题并收集其他工具无法收集的指标。
LLMs aren't great for working with anything beyond text. But now you can serve BLIP-2 with Jina and DocArray, enhancing LLMs with visual understanding
Blip is a new open source MySQL metrics collector, or “MySQL monitor” for short. But isn’t collecting MySQL metrics easy? And don’t we already have some open source MySQL monitors? Let’s take a...
完成下面两步后,将自动完成登录并继续当前操作。