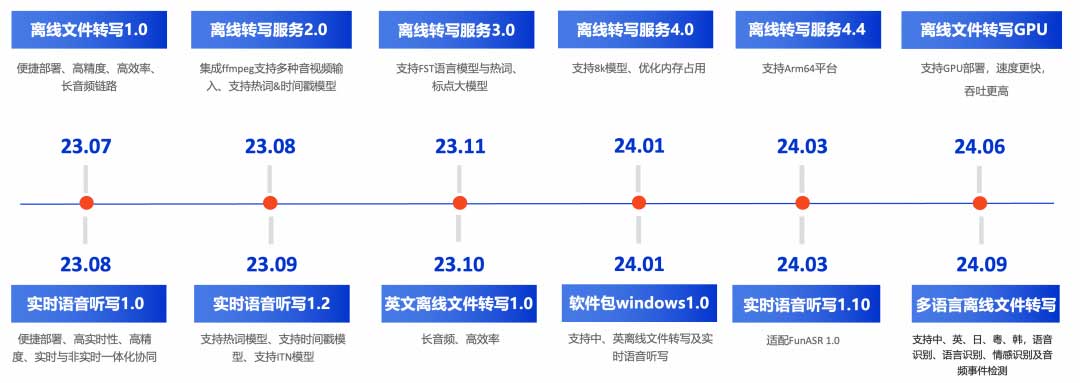
阿里达摩院开源了大型语音识别工具包FunASR,核心模型Paraformer经过60,000小时的普通话语音数据训练,具备高精度识别能力。该工具包还包括语音活动检测和文本后处理模型,性能优于Whisper,适用于长音频识别服务。
FunASR是通义实验室开源的语音识别框架,集成语音端点检测、语音识别和标点预测,支持多语言离线转写。其SenseVoiceSmall模型支持中、英、日、粤、韩五种语言,具备语音、语言、情感识别及音频事件检测能力,适用于实时语音交互。FunASR支持Docker部署,提供多种测试方式。
最近在做大模型相关的项目,其中有个模块需要提取在线视频语音为文本并输出给用户。通过调研和实践,成功实现了抓取在线视频、视频转语音和语音转文本的功能。具体实现方案包括使用selenium提取网页中的视频、使用FFmpeg将视频分割为音频文件以及使用funasr进行语音转文本。最终能够在本地电脑实现抓取在线视频并提取视频语音为文本。
阿里达摩院自研的FunAsr是一款中文语音识别技术,与OpenAi的Whisper相媲美。FunAsr基于Paraformer非自回归端到端模型,具有高精度、高效率、便捷部署的优点,支持标点符号识别、低语音识别、音频-视觉语音识别等功能。通过对比测试,FunAsr在中文语音转写方面表现优秀,几乎每一条素材都进行了标注。与Whisper相比,FunAsr的模型参数更多,训练数据更丰富,因此在中文领域的语音识别效果更好。
完成下面两步后,将自动完成登录并继续当前操作。