
开源上新|FunASR多语言离线文件转写软件包
内容提要
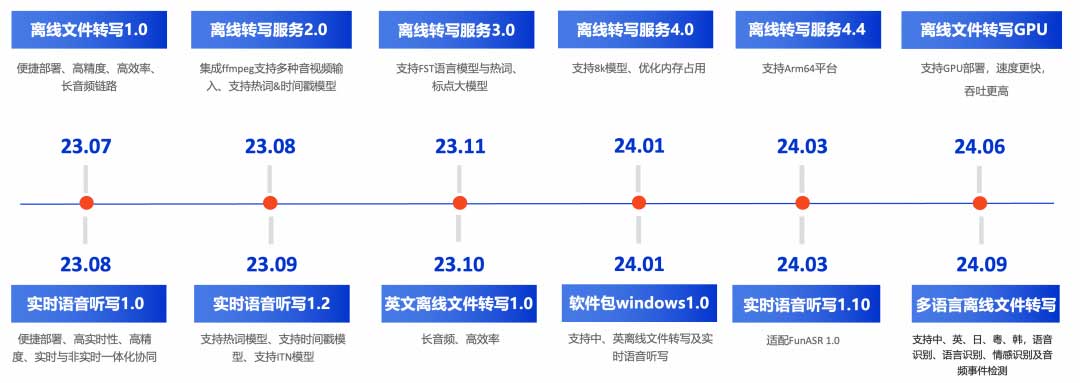
FunASR是通义实验室开源的语音识别框架,集成语音端点检测、语音识别和标点预测,支持多语言离线转写。其SenseVoiceSmall模型支持中、英、日、粤、韩五种语言,具备语音、语言、情感识别及音频事件检测能力,适用于实时语音交互。FunASR支持Docker部署,提供多种测试方式。
关键要点
-
FunASR是通义实验室开源的语音识别框架,集成语音端点检测、语音识别和标点预测。
-
支持多语言离线转写,SenseVoiceSmall模型支持中、英、日、粤、韩五种语言。
-
具备语音识别、语言识别、情感识别及音频事件检测能力,适用于实时语音交互。
-
FunASR支持Docker部署,提供多种测试方式。
-
软件包安装步骤简便,用户可通过Docker快速安装和启动服务。
-
支持多种音频格式输入,并提供HTML网页客户端进行体验。
-
感谢众多开发者的参与与支持,推动开源项目的发展。
延伸解读
多语言支持的优势
FunASR的SenseVoiceSmall模型支持中、英、日、粤、韩五种语言,这使得其在全球化应用中具有显著优势。用户可以在不同语言环境中实现高效的语音转写,适用于多种行业,如教育、客服和媒体等,提升了跨语言沟通的效率。
Docker化部署的便利性
FunASR支持Docker部署,简化了安装和配置过程。用户只需通过简单的命令即可快速启动服务,这对于开发者和企业来说,降低了技术门槛,节省了时间,便于快速集成语音识别功能到现有系统中。
实时语音交互的应用场景
由于SenseVoiceSmall模型具备快速响应能力,FunASR特别适合实时语音交互应用,如智能助手和在线客服。这种低延迟特性使得用户体验更加流畅,能够满足对即时反馈的需求,提升用户满意度。
延伸问答
FunASR是什么?
FunASR是通义实验室开源的语音识别框架,集成了语音端点检测、语音识别和标点预测等功能。
FunASR支持哪些语言的离线转写?
FunASR的SenseVoiceSmall模型支持中、英、日、粤、韩五种语言的离线转写。
如何安装和部署FunASR?
用户可以通过Docker快速安装和启动FunASR,具体步骤包括安装Docker、拉取镜像和启动服务。
FunASR有哪些语音理解能力?
FunASR具备语音识别、语言识别、情感识别及音频事件检测能力。
FunASR适合哪些应用场景?
FunASR适用于实时语音交互和高并发的文件转写场景。
如何使用FunASR的网页客户端进行测试?
用户可以在浏览器中打开指定的HTML页面,输入服务器IP与端口号后进行体验。
