Google Research unveiled TurboQuant, a novel quantization algorithm that compresses large language models’ Key-Value caches by up to 6x. With 3.5-bit compression, near-zero accuracy loss, and no...
Madelyn Olson discusses the evolution of Valkey's data structures, moving away from "textbook" pointer-chasing HashMaps to more cache-aware designs. She explains the implementation of "Swedish"...
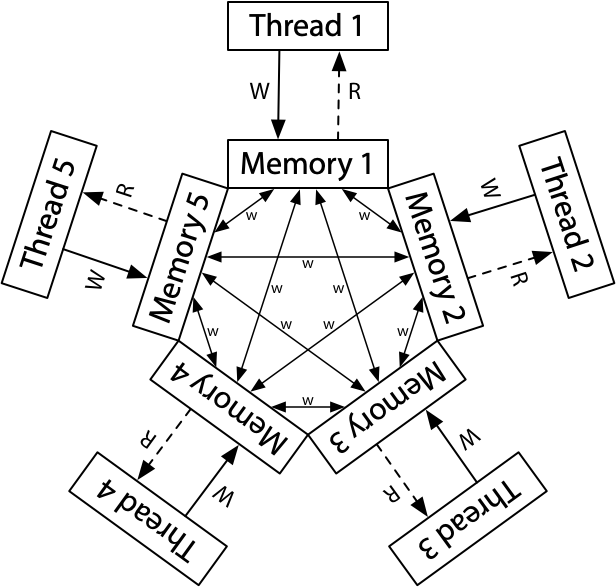
本文探讨了硬件内存模型对多线程程序的影响。随着多核处理器的普及,程序员需理解内存一致性问题及硬件和编译器优化对程序行为的影响。顺序一致性是理想模型,但现代硬件常偏离此模型,导致程序在不同平台上表现不一致。文章还讨论了通过内存屏障等手段确保程序正确性的方法。
本研究探讨了DeepSeek-V3在扩展大型语言模型时的硬件限制,并提出了一种新颖的硬件感知模型设计方法。通过引入多头潜在注意力机制和FP8混合精度训练,DeepSeek-V3实现了高效的训练和推理,推动了下一代AI系统的发展。
本研究展示了一种新型量子回声状态网络(QESN),用于在噪声环境中预测混沌状态。实验结果表明,该方法在长期时间序列预测中表现优异,显示了量子计算在机器学习中的应用潜力。
本文探讨在无额外计算资源的情况下,大型语言模型(LLM)能力的提升。作者提出了一个分类框架,区分依赖计算与独立于计算的创新,结果表明,计算独立的创新在资源受限环境中显著提升了性能。
本研究提出了一种层次稀疏注意力(HSA)机制,解决了递归神经网络(RNN)在随机访问历史上下文方面的局限性。结合HSA与Mamba形成的RAMba在6400万上下文中实现了完美的密码检索准确率,展示了其在长上下文建模中的潜力。
本文探讨了摩尔定律在现代计算中的局限性,强调硬件与软件协同设计对满足性能需求的重要性,并指出打破传统界限有助于重新定义计算机设计原则,推动新一代计算的进步。
本研究提出了CARE模型,通过QLoRA微调Phi3.5-mini,实现了在极少硬件和数据下的快速学习,解决了大语言模型在特定领域问答的时间和成本问题。CARE在电信、医疗和银行等领域表现良好,尤其在医疗基准测试中显示出提供基本医疗建议的潜力。
本研究提出了一种基于大型语言模型(LLM)的优化框架,能够自动重构代码以应对硬件设计的挑战。实验结果表明,该模型在成功率、效率和设计质量上优于传统LLM,为硬件设计提供了新的视角。
本研究提出了一种三层解耦架构,解决了大语言模型应用中的平台孤岛、硬件集成碎片化和标准化接口缺乏的问题,从而提升了应用效率,并为安全可扩展的AI部署提供了新视角。
演讲者Timothy Roscoe在USENIX ATC '21和OSDI '21的主题演讲中强调,操作系统应重新关注硬件。
Hardware.Info 是一个跨平台的硬件信息查询库,支持 Windows、Linux 和 macOS,能够获取电池、CPU、内存和存储等硬件信息,提供详细数据。尽管存在查询延迟和数据无效的问题,但可通过适当配置加以解决。
本研究提出了一种结合强化学习与卷积神经网络的方法,以提高在量子硬件上为大规模Sachdev-Ye-Kitaev模型(N>12)准备热态的效率。该方法通过优化量子电路,显著减少了CNOT门的数量,并在不同量子环境中展示了高效性和准确性,对量子多体系统和量子引力研究具有重要意义。
本研究将卡拉茨巴算法扩展至矩阵乘法,设计了高效的硬件架构,显著降低了额外加法复杂度,提高了深度学习加速器的性能。
本研究提出了集成方案RouteNet-Gauss,结合实验网络与机器学习,显著提升了网络模拟的效率和准确性,推理时间缩短至原来的1/488,预测误差降低95%。
本文提出了一种名为RTLMarker的硬件水印框架,旨在有效保护RTL代码的版权。通过规则驱动的Verilog代码变换,确保水印的正确性,并优化水印的透明度与有效性。研究表明,RTLMarker在水印效果上显著优于现有方法。
Software-defined hardware is reshaping multiple industries as advances in AI enable new capabilities and dramatically reduce development costs.
本研究提出了一种基于深度展开的结构化学习迭代收缩和阈值算法(S-LISTA),旨在提高单快照多维谐波检索的准确性和能效。经过在SpiNNaker2硬件上的验证,能效提升近五倍,尽管性能略有下降。
本研究提出了SoftmAP方法,旨在解决大语言模型在资源受限设备上的计算和内存开销问题。该方法通过利用内存计算硬件实现低精度Softmax,仅使用整数,从而显著提高能量延迟产品,提升模型的可部署性而不损失性能。
完成下面两步后,将自动完成登录并继续当前操作。