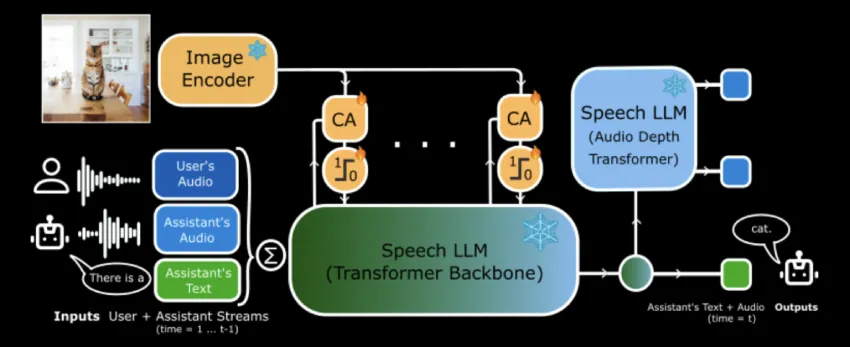
MoshiVis是一种开源视觉语音模型,结合实时语音交互与视觉内容,提升了对视觉场景的描述能力,特别适合视障人士。它通过轻量级交叉注意模块增强语音模型,确保低延迟和高效能,促进自然交互与可访问性。
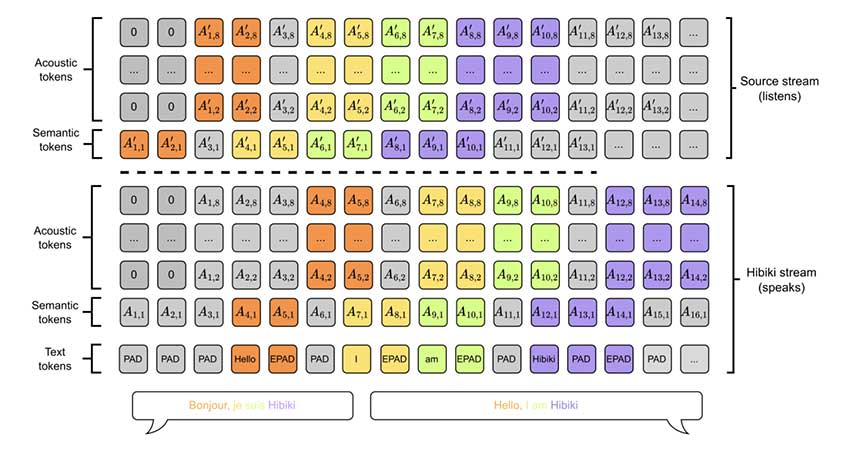
Hibiki是一个实时语音翻译模型,结合语音识别、机器翻译和文本转语音,支持法语到英语翻译。其独特架构和上下文对齐技术提升了翻译质量和说话人保真度,适合实时应用。Hibiki-M优化了智能手机性能,具备开源潜力。
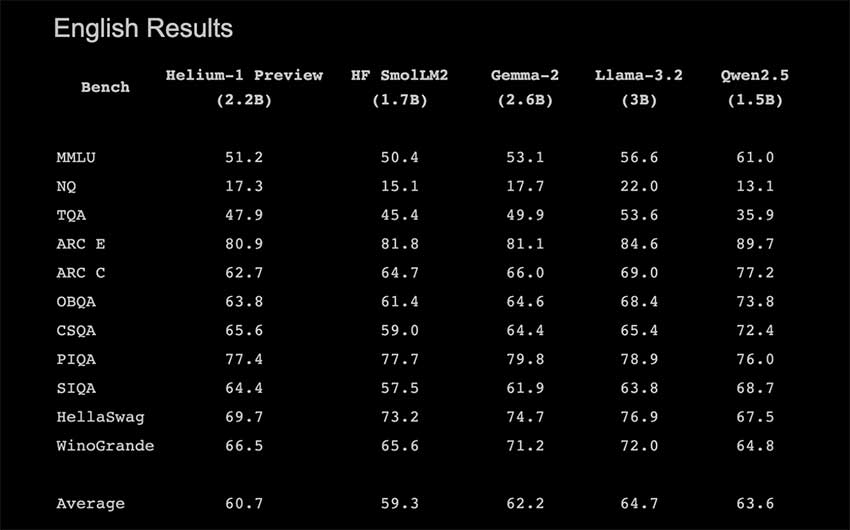
Helium-1 Preview是一款针对边缘和移动设备的多语言基础LLM,拥有20亿参数,优化了计算效率和多语言能力,适合对话式AI和实时翻译等应用。其开源特性促进了创新,标志着AI技术在边缘设备上的重要进展。
Moshi是一款实时口头对话系统,具有连贯且上下文准确的语音生成功能,延迟仅为160毫秒。它能够处理重叠语音和中断,语音质量好且易懂。Moshi能够维持长时间对话,上下文跨度超过五分钟,并在口头问答任务中表现出色。它代表了口头对话系统的重大飞跃,树立了新标准。
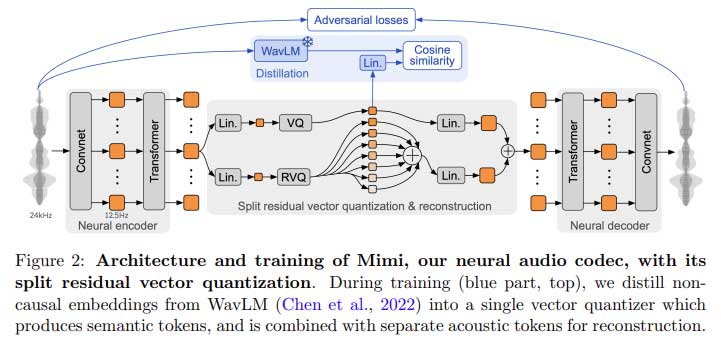
法国创业团队Kyutai发布了开源实时音频模型Moshi,包括Moshiko、Moshika和Mimi流语音编解码器。Moshi在MacBook上运行,延迟约200毫秒,使用了Mimi流式神经音频编解码器和RQ-Transformer变体架构。Moshi在质量、音频语言建模和口语问答方面表现优秀。OpenAI的高级语音模式可能在9月24日发布。
苹果任命菲尔·席勒为OpenAI董事会观察员,以整合ChatGPT到其设备中。OpenAI的ChatGPT macOS应用更新加密对话以保护用户隐私。Kyutai开源了Moshi,一个实时本地多模态人工智能模型。
完成下面两步后,将自动完成登录并继续当前操作。