
Kyutai Labs 发布 Helium-1 预览版:具有 2B 参数的轻量级语言模型,针对边缘和移动设备
内容提要
Helium-1 Preview是一款针对边缘和移动设备的多语言基础LLM,拥有20亿参数,优化了计算效率和多语言能力,适合对话式AI和实时翻译等应用。其开源特性促进了创新,标志着AI技术在边缘设备上的重要进展。
关键要点
-
边缘和移动设备对AI模型的依赖增加,面临计算效率、模型大小和多语言能力的挑战。
-
传统大型语言模型不适合边缘应用,因为它们需要大量资源。
-
Helium-1 Preview是针对边缘和移动环境的20亿参数多语言基础LLM,优化了计算效率和多语言能力。
-
Helium-1的设计性能与其他模型相当,且保持紧凑高效,适合资源有限的环境。
-
该模型经过2.5万亿个token的训练,支持4096个token的上下文大小,适合处理长文本。
-
Helium-1专为资源受限环境设计,减少延迟和内存使用,适合移动和物联网应用。
-
CC-BY许可证确保开发人员可以自由调整和构建模型,鼓励创新。
-
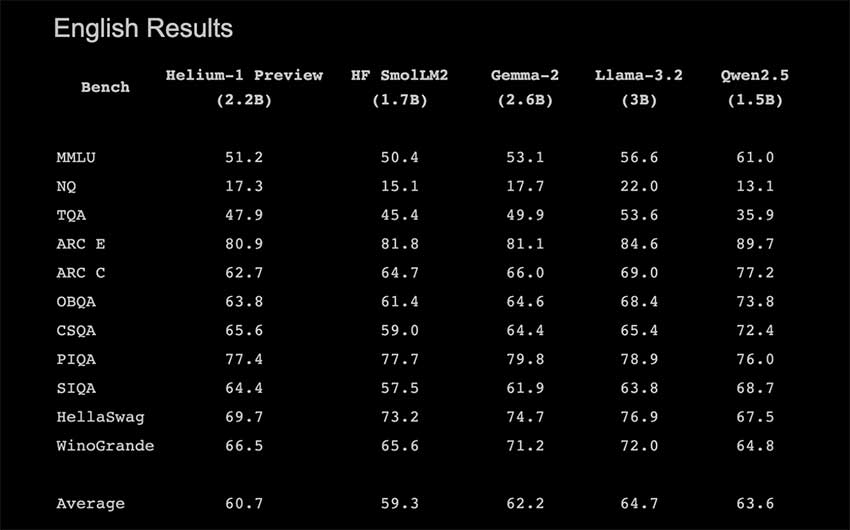
初步评估显示Helium-1在多语言基准测试中表现优异,超越或匹敌其他模型。
-
Helium-1适合对话式AI、实时翻译和移动内容摘要等应用,表现出多功能性。
-
Helium-1代表了在边缘和移动平台上部署AI模型的重大进展,树立了未来发展的先例。
延伸解读
边缘设备的AI需求
随着边缘和移动设备对AI模型的依赖增加,Helium-1的发布正好满足了这一需求。传统大型语言模型在资源受限的环境中难以应用,而Helium-1通过优化计算效率和多语言能力,提供了一个可行的解决方案,适合智能手机和物联网设备。
开源特性与创新
Helium-1采用CC-BY许可证,允许开发者自由调整和构建模型。这种开源特性不仅促进了技术的透明性,还鼓励了社区的创新,可能会催生出更多针对特定应用的优化版本,推动AI技术的进一步发展。
多语言能力的重要性
Helium-1在多语言基准测试中表现优异,显示出其在处理多种语言时的强大能力。这一特性使其特别适合全球化应用,如实时翻译和对话式AI,能够满足不同用户的需求,提升用户体验。
延伸问答
Helium-1模型的主要特点是什么?
Helium-1模型拥有20亿参数,优化了计算效率和多语言能力,适合边缘和移动设备。
Helium-1模型适合哪些应用场景?
Helium-1适合对话式AI、实时翻译和移动内容摘要等应用。
Helium-1是如何优化以适应边缘设备的?
Helium-1专为资源受限环境设计,减少延迟和内存使用,确保高效性能。
Helium-1的训练数据量是多少?
Helium-1经过2.5万亿个token的训练。
Helium-1的开源特性有什么意义?
Helium-1在CC-BY许可证下发布,鼓励开发者自由调整和构建模型,促进创新。
Helium-1在多语言基准测试中的表现如何?
Helium-1在多语言基准测试中表现优异,超越或匹敌其他模型。
