本文探讨了英伟达的视觉语言模型Eagle 2,强调数据策略在模型开发中的关键作用。作者详细介绍了数据收集、过滤和选择的方法,提出多样化数据可提升模型性能。Eagle 2在多模态基准测试中表现出色,展示了开源视觉语言模型的潜力与发展方向。
本研究解决了社交沟通中对高效计算机视觉工具的需求,提出了一种多模态大语言模型Face-LLaVA,用于面部表情和属性的识别以及自然语言生成。通过构建针对面部处理的FaceInstruct-1M数据库和独特的面部特征编码器,该模型在多个数据集和任务中表现优异,显示出相较于现有模型的显著优势和对社会AI发展的潜在影响。
小型多模态模型LLaVA-Rad专注于胸部X光影像,能够自动生成高质量的放射学报告,展现出在生物医学应用中的潜力。该模型在多个数据集上表现优异,计算效率高,适合临床应用。
在数字化时代,在线旅行预订平台面临酒店图片分类的挑战。传统人工分类效率低,需自动化解决方案。本文介绍利用Amazon SageMaker和LLaVA模型实现酒店图片的高效、低成本自动分类,以提升用户体验和运营效率。
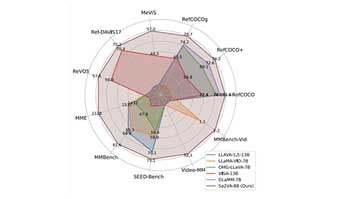
AIxiv报道了字节跳动与北大等机构联合提出的多模态大模型Sa2VA,该模型结合了SAM-2和LLaVA的优势,实现了视频和图像的细粒度理解,支持多种任务,表现优异。
AIxiv专栏促进了学术交流,报道超过2000篇内容。中国科学院团队提出的LLaVA-Mini通过将视觉tokens压缩至1个,显著提高了图像和视频理解效率,计算负载减少77%,响应延迟低于40毫秒,支持长视频处理。LLaVA-Mini在多模态交互中表现优异,但在处理精细视觉任务时可能存在限制。
多模态大型语言模型Sa2VA结合视频分割与语言处理,提升图像和视频理解效率。该模型采用创新的解耦设计和特殊标记机制,支持多任务,表现优于以往系统,标志着多模态AI的重大进步。
AIxiv专栏促进学术交流,报道2000多篇多模态模型研究。南洋理工大学LMMs-Lab团队通过“模型看模型”方法,探讨神经元功能,旨在减少模型幻觉并提升安全性。
中国研究人员优化了Llama-3.2-11B-Vision-Instruct,开发了LLava-CoT模型,显著提升了多模态推理能力,尤其在视觉问答和数学推理任务中表现优异。
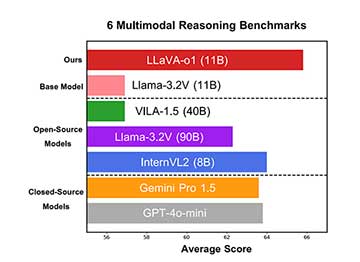
LLaVA-o1是一种新型视觉语言模型,采用四阶段推理结构和阶段级束搜索技术,显著提升了多模态任务的推理准确性和效率。实验结果显示,其在多个基准测试中表现优异,推动了视觉与文本处理的发展。
本文综述了多模态大型语言模型(MLLMs)的最新进展,重点介绍了TinyGPT-V、Mipha和EE-MLLM等模型的设计与应用。研究分析了这些模型在视觉、语言和音频任务中的表现,并提出了知识蒸馏和新架构以提升效率。未来的研究方向将集中在优化计算资源和提升模型性能上。
YOLO是一种高效的目标检测方法,能够实时识别交通标志。研究提出了改进的MFL-YOLO模型,提升了检测精度和效率。在郊区社区的交通标志检测中,系统达到了96%的准确率,显示出改善道路安全的潜力。此外,研究还探讨了不同天气条件下的物体检测性能,为自动驾驶技术的发展提供支持。
本文介绍了医学图像与语言模型的研究进展,包括生成自然语言解释以验证医学图像预测的正确性,提出了MIMIC-NLE数据集及多种模型框架(如LLaVA-Med、PA-LLaVA),旨在提高医学诊断的准确性和实用性。同时,研究探讨了数据隐私和模型可解释性等挑战,并提出未来研究方向。
本研究解决了多模态大型语言模型(MLLM)数据质量变异性的问题,通过提出一种新颖的指令策划算法,将人类与LLM的偏好对齐。研究显示,通过优化指令数据集,我们能将训练样本数量从158k减少到14k,同时在各种MLLM基准上表现优于使用全量数据集的模型,从而显著提高系统的效率和效果。
研究提出了LLaVA-3D框架,将LLaVA的2D理解与3D Patch结合,提升3D场景理解。实验显示其训练速度和性能优于现有3D多模态模型。还介绍了Chat-3D、LL3DA等3D语言模型,展示了在3D场景理解和对话中的应用优势。
本文介绍了一种无监督学习任务,联合建模视觉场景图和语言依赖树,构建了VLParse数据集,并提出了VLGAE框架用于视觉语言短语理解。研究强调了视觉信息和语言依赖关系在VL结构建模中的重要性,并提出了VLUE评估基准,以评估视觉语言处理模型的泛化能力和效率。此外,探讨了通过小型数据集和新训练范式提升VL模型表现的方法,推动了大规模视觉语言模型的发展。
该研究解决了在线食谱分享中对有效生成食品食谱的需求,提出了一种新颖的模型LLaVA-Chef,该模型经过针对多样食谱提示的定制数据集训练,以提高食品领域的理解能力。研究发现,LLaVA-Chef生成的食谱在成分提及的准确性和细节方面显著优于现有方法,显示出其在食品生成任务中的潜在影响。
本文介绍了针对大型语言模型(LLMs)和多模态学习的创新方法,如MiniLLM、u-LLaVA和MoE-LLaVA。这些方法通过优化模型结构和训练策略,提升了模型在视觉理解和对话任务中的性能,展示了小型模型在资源效率和复杂交互中的潜力。此外,研究探讨了知识蒸馏技术在提升小规模模型性能方面的应用,为未来的多模态学习系统提供了新思路。
本研究通过构建新数据集Surg-QA,包含102,000个外科视频-指令对,并采用两阶段问答生成管道,提高了外科视频的多模态对话能力。研究结果显示,LLaVA-Surg在开放式外科视频问答任务中性能明显超越之前的模型,展现出卓越的多模态对话能力。
该研究提出了多模态大规模视觉语言模型(LVLM)及相关方法,如u-LLaVA和ViLaM,旨在解决任务间干扰问题,提升视觉与语言任务的性能。通过优化数据质量和训练配方,较小模型也能达到与大模型相当的效果,展示了在医学图像分析等领域的潜力。
完成下面两步后,将自动完成登录并继续当前操作。