
LLaVA-o1:一个能够进行与 GPT-o1 类似的自发、系统推理的视觉语言模型
内容提要
LLaVA-o1是一种新型视觉语言模型,采用四阶段推理结构和阶段级束搜索技术,显著提升了多模态任务的推理准确性和效率。实验结果显示,其在多个基准测试中表现优异,推动了视觉与文本处理的发展。
关键要点
-
LLaVA-o1是一种新型视觉语言模型,采用四阶段推理结构和阶段级束搜索技术。
-
该模型显著提升了多模态任务的推理准确性和效率。
-
LLaVA-o1拥有110亿个参数,旨在进行自主、多阶段推理。
-
模型的四个推理阶段包括摘要、标题、推理和结论。
-
LLaVA-o1使用LLaVA-o1-100k数据集进行微调,提升了多模态推理基准测试的表现。
-
与传统方法相比,LLaVA-o1通过阶段级束搜索生成多个响应,确保更高质量的结果。
-
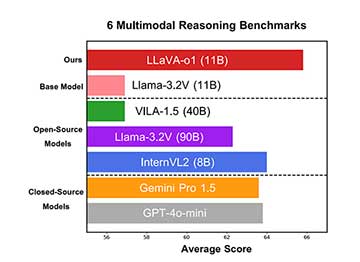
实验结果显示,LLaVA-o1在多个基准测试中表现优异,尤其在数学和科学视觉问题上。
-
LLaVA-o1为多模态AI树立了新的标杆,证明了高效的多模态推理无需大型闭源模型的资源。
延伸解读
多模态推理的突破
LLaVA-o1通过引入四阶段推理结构,显著提升了视觉语言模型在多模态任务中的表现。这种结构化的推理方法不仅提高了准确性,还确保了逻辑连贯性,解决了传统模型在处理复杂视觉问答时的局限性。
阶段级束搜索的优势
LLaVA-o1采用的阶段级束搜索技术,使得每个推理阶段都能生成多个候选响应并进行验证。这种方法相比传统的推理方式,能够有效减少错误,提高了模型在复杂任务中的可靠性和一致性。
高效的训练策略
LLaVA-o1在仅使用100,000个训练样本的情况下,便实现了优于许多大型模型的性能。这表明,通过合理的模型设计和数据集选择,较小规模的模型也能在多模态推理中取得显著成果,降低了资源需求。
延伸问答
LLaVA-o1模型的主要特点是什么?
LLaVA-o1是一种新型视觉语言模型,采用四阶段推理结构和阶段级束搜索技术,拥有110亿个参数,旨在进行自主、多阶段推理。
LLaVA-o1如何提升多模态任务的推理准确性?
LLaVA-o1通过四个推理阶段(摘要、标题、推理和结论)和阶段级束搜索技术,生成多个响应并选择最佳候选,从而提高推理准确性。
LLaVA-o1在基准测试中的表现如何?
LLaVA-o1在多个基准测试中表现优异,尤其在数学和科学视觉问题上,其多模态推理基准测试提高了8.9%。
LLaVA-o1与传统视觉语言模型相比有什么优势?
LLaVA-o1通过结构化推理和阶段级束搜索,确保逻辑连贯性和高质量结果,克服了传统模型的即时响应和推理错误问题。
LLaVA-o1的训练数据集是什么?
LLaVA-o1使用名为LLaVA-o1-100k的数据集进行微调,该数据集来自视觉问答源和GPT-4o生成的结构化推理注释。
LLaVA-o1对未来视觉语言模型研究有什么影响?
LLaVA-o1为未来在视觉语言模型中进行结构化推理的研究铺平了道路,有望在视觉和文本领域实现更先进的AI驱动认知处理能力。
