机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
机器之心数据服务已上线,提供高效稳定的数据获取,简化数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
CVPR2025提出的Video-Bench框架通过模拟人类认知,评估AI生成视频的质量与美学,解决了视频与文本对齐的问题。该框架采用链式查询和少样本评分技术,显著提高了评估准确性,超越了传统方法。
本研究提出了一种“基于确定性的自适应推理”(CAR)框架,旨在提高大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的推理效率。CAR通过动态调整简短回答与长形式推理,提升了简单任务的性能,并在多模态基准测试中展现了更好的准确性和效率平衡。
UFO是一种新型多模态大模型,通过特征检索实现细粒度视觉感知,无需额外解码器,表现优异,支持文本输出,简化任务复杂性,提升性能。
本研究提出了一种新的知识解耦协同学习方法(KDSL),有效解决电子商务中少样本多模态对话意图识别的干扰问题。在淘宝数据集上,该方法的F1分数提升了6.37%和6.28%,验证了其有效性。
多模态大语言模型(MLLM)结合语言、视觉和音频等信息处理能力,近年来在计算机视觉领域取得显著进展,广泛应用于医疗和自动驾驶等场景。顶尖模型如GPT-4o和Apple Ferret展现出强大的理解与生成能力,但在高难度任务中仍需提升。
本研究提出了一种集体蒙特卡罗树搜索(CoMCTS)方法,以提高多模型大语言模型(MLLM)的推理效率。实验结果显示,基于CoMCTS训练的Mulberry模型在基准任务中表现优异,具有良好的应用前景。
研究者们计划在2025年实现AI领域的突破,特别是在空间思维方面。他们提出了VSI-Bench,这是一个基于视频的基准测试,用于评估多模态大语言模型(MLLM)在视觉空间智能方面的表现。尽管与人类相比仍有差距,但模型展现出新兴的视觉空间智能。研究指出,空间推理是MLLM的主要瓶颈,未来的AI助手需要更好地理解和导航空间。
本研究提出了新模型CCExpert,结合差异感知集成模块与高质量数据集CC-Foundation,显著提升了遥感图像变化检测的性能,展现出巨大潜力。
本文提出了一种统一的计算机辅助设计生成系统CAD-MLLM,能够根据文本描述、图像和点云等多模态输入生成CAD模型。研究表明,CAD-MLLM在模型质量及对噪声和缺失点的鲁棒性方面显著优于现有方法,具有重要的应用价值。
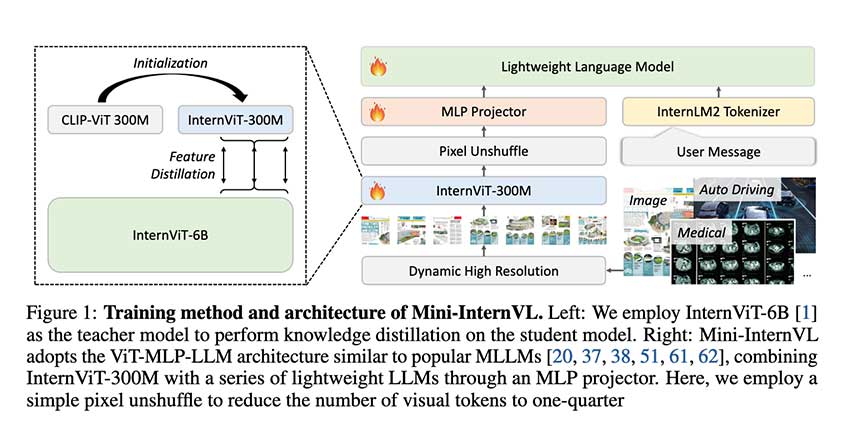
多模态大型语言模型(MLLM)迅速发展,结合视觉与语言处理,提升数据理解能力。Mini-InternVL系列轻量级MLLM通过减少参数,实现高效的多模态理解,适用于自动驾驶和医学成像等领域,表现出色。该模型在多个基准测试中展现出强大的适应性和性能,为资源有限的环境提供了可扩展的解决方案。
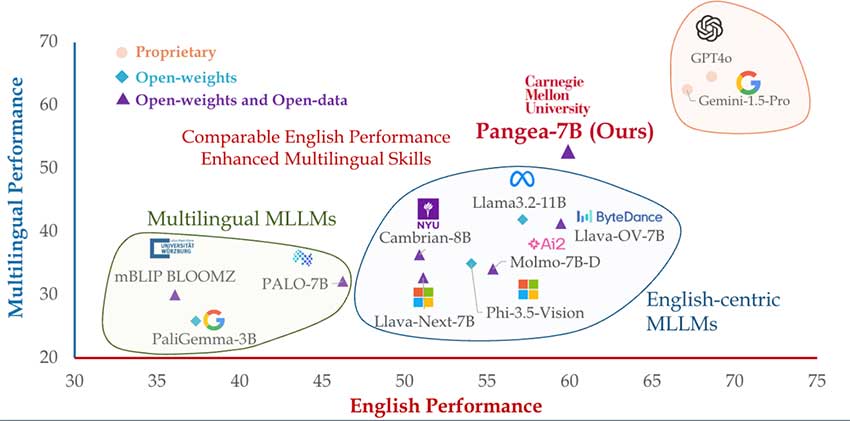
尽管多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化的代表性仍不足。卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。评估结果显示,PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。该模型的开源有望提升跨语言和文化的公平性与可访问性。
人工智能中的多模态学习迅速发展,Ovis 1.6 通过视觉嵌入表对齐视觉和文本数据,解决嵌入不一致问题。在多项测试中表现优异,展示了其在复杂任务中的潜力。
本文探讨了集体照片中个体的重要性,提出了一种基于视觉线索的自动预测方法,显著改善了人群图像描述效果。研究涉及神经网络检测社交行为、多人语义分割和重要人物检测,展示了在多个数据集上的优异性能,并提出了新的预训练框架和注意力估计方法,推动了人类行为分析和自动驾驶等领域的发展。
本文介绍了新型超分辨率图像生成模型,如Diff-SR和HiDiffusion,这些模型通过低分辨率图像生成高分辨率图像,显著提升了生成质量和效率。研究显示,这些模型在训练和推理中表现出色,解决了现有模型的语义不准确和对象复制等问题,为未来图像合成研究提供了新思路。
本文综述了多模态大型语言模型(MLLMs)的最新进展,包括技术、应用及挑战。MLLMs结合文本和视觉数据,展现了生成图像叙述的能力,但仍需解决多模态语义差距问题。研究探讨了模态对齐方法及其在视觉定位和图像生成等任务中的应用,为未来研究提供了方向。
该研究提出了一种名为RAAT的新方法,将大型语言模型与检索增强生成结合,显著提高了模型在噪声条件下的表现。通过多任务学习和适应性对抗训练,模型在细粒度视觉识别和零次识别任务中提升了准确性。文章还回顾了检索增强生成技术的现状及未来挑战,强调了知识更新和领域专长的关键问题。
本文分析了医学生成型问答系统中的幻觉现象,并提出交互自我反思方法以减少幻觉。同时,研究探讨了多模态大型语言模型中的幻觉问题,提出多种减轻策略,以提高模型的可靠性和准确性。
完成下面两步后,将自动完成登录并继续当前操作。