

刚刚,全球首个具身专属的MoE视频模型,开源了!
量子位
·


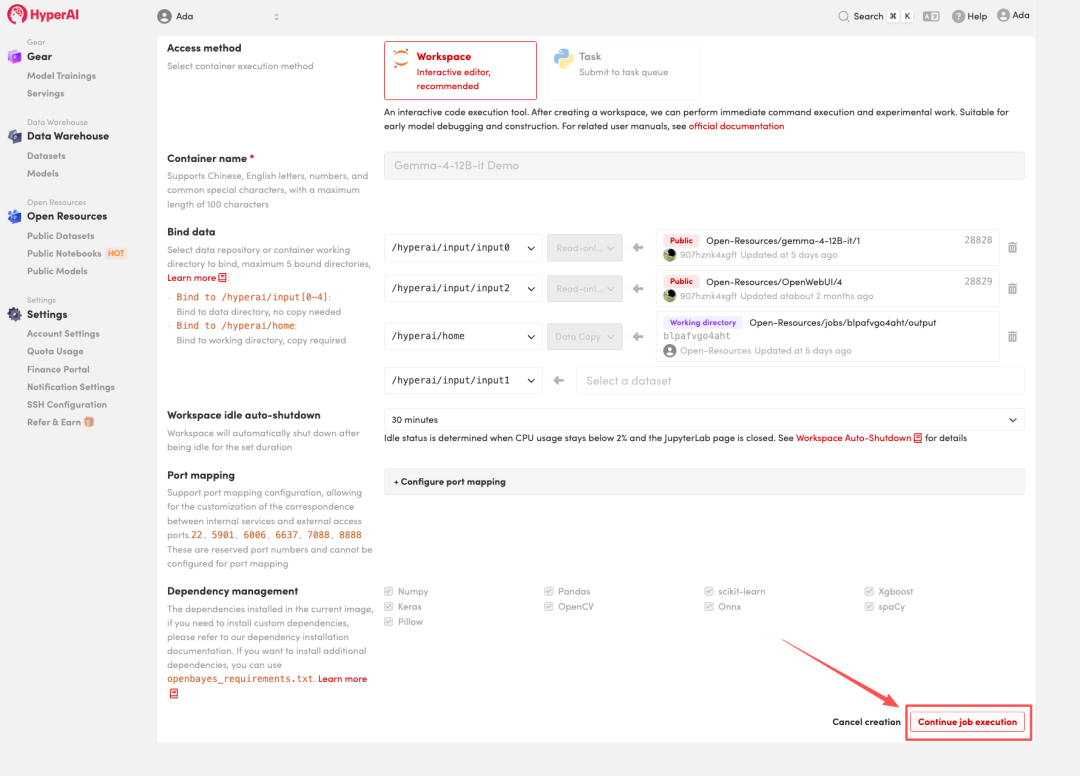
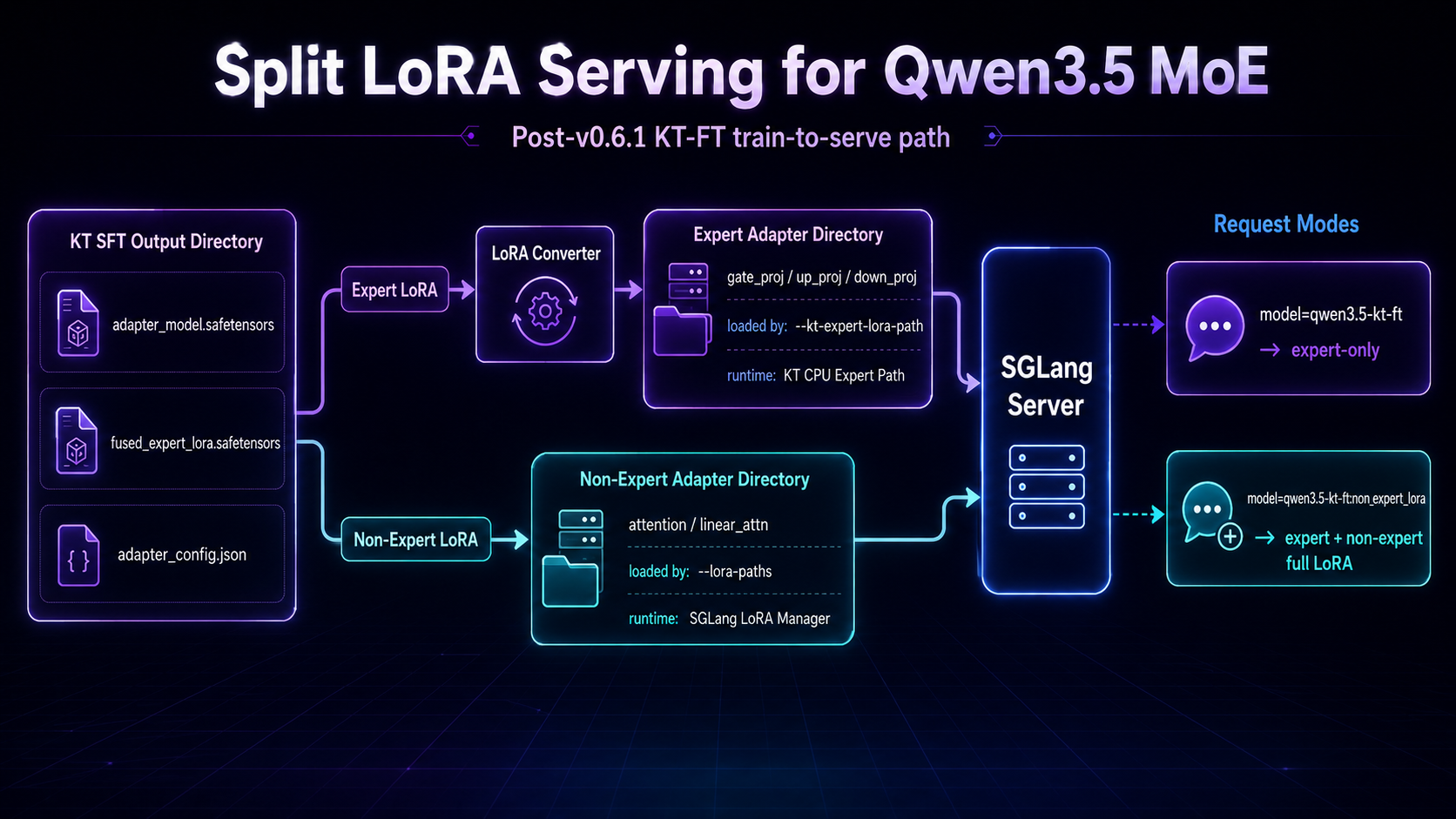
KT-FT v0.6.1:实现从MoE微调到本地服务的完整闭环
Home | KVCache.ai
·
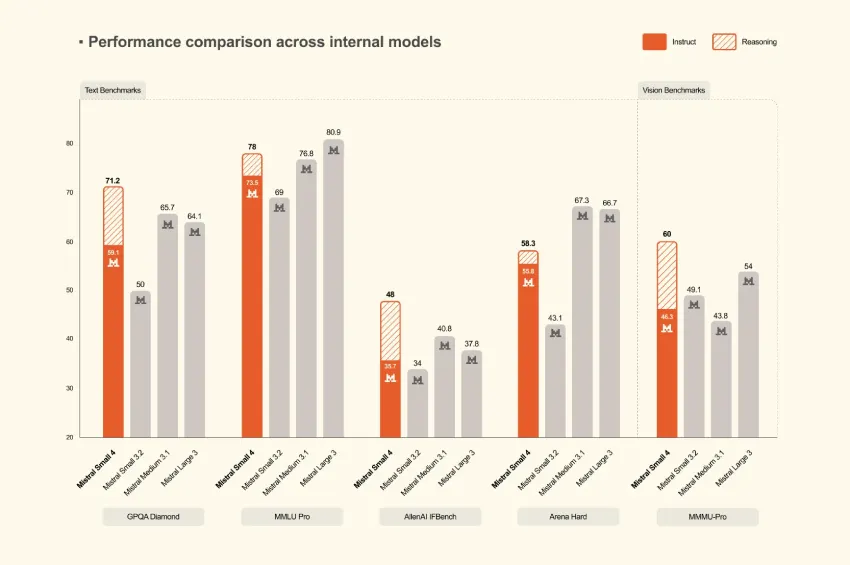

打破密集瓶颈:Voyage-4-large如何利用混合专家(MoE)进行扩展
Voyage AI
·


MoE比你想象的更强大:基于RoE的超并行推理扩展
Apple Machine Learning Research
·
