
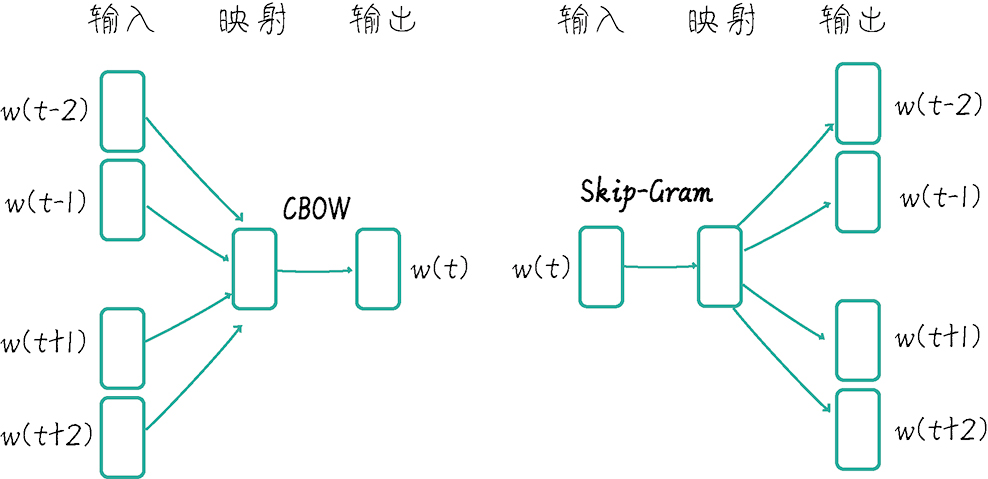
《GPT 图解》笔记:N-Gram、NPLM、LSTM
Ying’s Blog
·

如何使用 MySQL 全文检索
人言兑
·
/cdn.vox-cdn.com/uploads/chorus_asset/file/24016884/STK093_Google_05.jpg)
谷歌图书 reportedly 正在索引低质量的AI生成作品
The Verge
·
Python Load 169
蠎周刊
·
