
《GPT 图解》笔记:N-Gram、NPLM、LSTM
内容提要
本文介绍了语言模型的发展历程,包括N-Gram、NPLM、RNN和LSTM等。N-Gram通过统计前n-1个词的概率进行预测,但缺乏泛化能力;NPLM引入词向量,具备一定的泛化能力;RNN和LSTM通过递归状态支持变长序列,解决了长期依赖问题。总结了N-Gram和Bag-of-Words的基本原理及应用。
关键要点
-
N-Gram模型通过统计前n-1个词的概率进行下一个词的预测,但缺乏泛化能力。
-
NPLM引入词向量embedding,具备一定的泛化能力,但仍然是固定窗口。
-
RNN和LSTM通过递归状态支持变长序列,解决了长期依赖问题。
-
N-Gram模型适用于文本生成,Bag-of-Words适用于文本相似度计算。
-
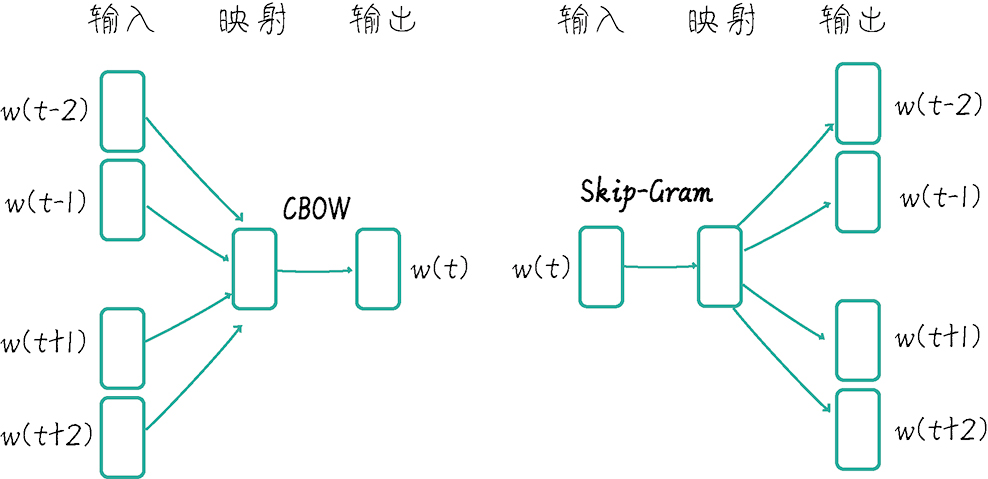
Word2Vec通过上下文预测任务学习词的稠密向量表示,能够捕捉更多信息。
-
NPLM通过embedding将离散token转换为连续向量,核心目标是预测下一个词。
-
RNN通过hidden state递归传递历史信息,支持变长序列,LSTM是其改进版本。
延伸解读
N-Gram模型的局限性
N-Gram模型虽然在文本生成中应用广泛,但其缺乏泛化能力,主要依赖于前n-1个词的统计信息。这使得模型在处理新颖或复杂句子时表现不佳,无法有效捕捉长距离依赖关系。
RNN与LSTM的优势
RNN和LSTM通过递归状态的设计,能够处理变长序列并有效解决长期依赖问题。相比于NPLM的固定窗口,LSTM的结构使其在语言建模中更具灵活性和准确性,适合复杂的语言任务。
Word2Vec与Bag-of-Words的比较
Word2Vec通过上下文学习词的稠密向量表示,能够捕捉词之间的语义关系,而Bag-of-Words则仅依赖词频统计,忽略词序信息。对于需要理解词义和上下文的任务,Word2Vec显然更具优势。
延伸问答
N-Gram模型的基本原理是什么?
N-Gram模型通过统计前n-1个词的概率来预测下一个词,但缺乏泛化能力。
NPLM与Word2Vec有什么区别?
NPLM的核心目标是预测下一个词,而Word2Vec的核心目标是学习词表示。
RNN和LSTM是如何解决长期依赖问题的?
RNN通过hidden state递归传递历史信息,而LSTM通过引入门控机制来更好地捕捉长期依赖。
Bag-of-Words模型适合用于什么场景?
Bag-of-Words模型适用于文本相似度计算,因为它记录了词汇表中每个词的出现次数。
Word2Vec的Skip-Gram模型是如何工作的?
Skip-Gram模型通过输入中心词来预测上下文中的词,从而学习词的稠密向量表示。
N-Gram模型的假设是什么?
N-Gram模型基于贾里尼克假设和一阶马尔可夫假设,认为一个词的出现概率只与前一个词有关。
