本文讨论了大语言模型(LLM)推理引擎的现代化技术,包括连续批处理和分页注意力。这些技术显著提升了LLM的吞吐量和GPU利用率,同时优化了显存利用率。文章还介绍了分块预填充和前缀缓存等策略,以降低延迟和提高效率,强调在生产环境中应用这些技术的重要性。
运行大型语言模型(LLM)如GPT的成本高,vLLM通过Paged Attention技术优化内存管理,提升KV缓存效率,支持多请求并行处理,从而提高模型服务性能。
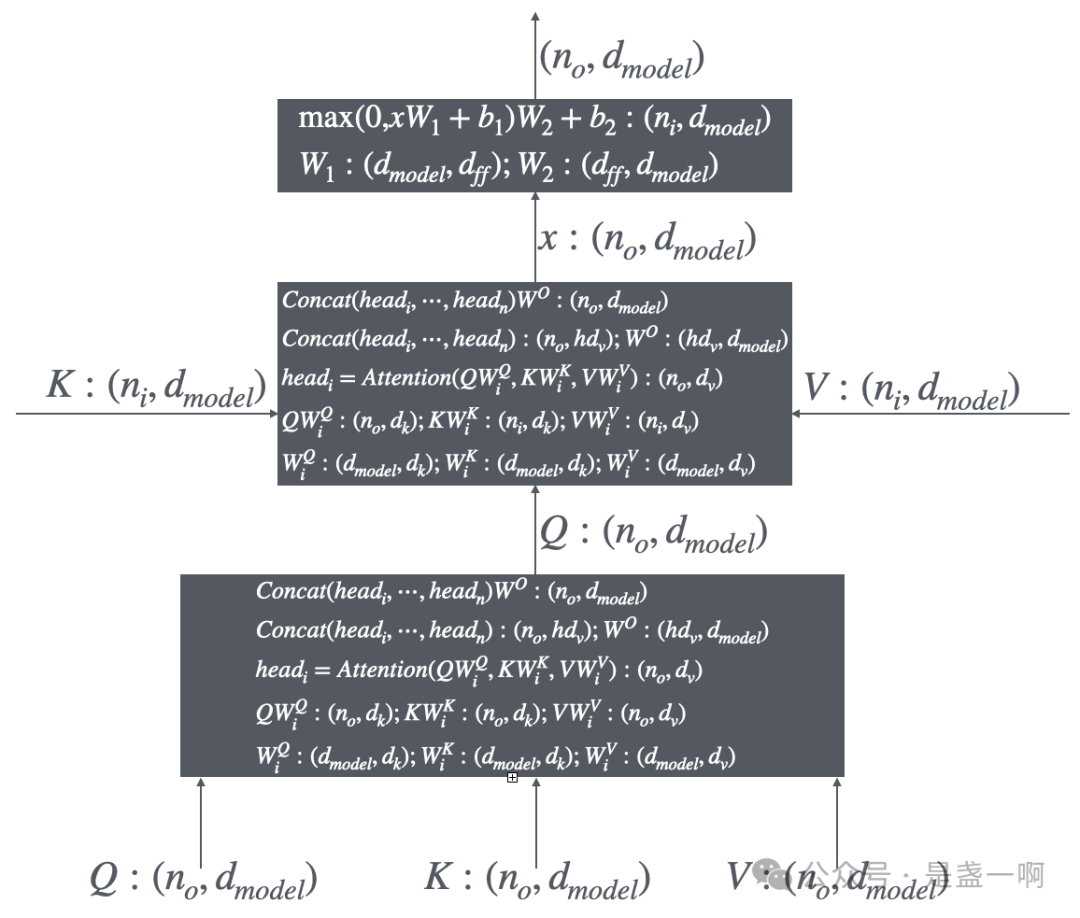
本文总结了Transformer模型的结构,重点介绍了编码器和解码器的输入输出关系。编码器处理用户输入的token并生成中间层输出;解码器根据编码器的输出逐步生成新的token。讨论了Masked Multi-Head Attention的作用,强调其对解码过程中因果性的影响,并指出GPT与Transformer的区别,GPT仅包含解码器并应用masked机制。
该文介绍了一种基于键值记忆的注意力机制模型,用于神经机器翻译。该模型通过维护键内存和固定值内存之间的转换和迭代交互,以便在每个解码步骤时,可以关注更合适的源单词来预测下一个目标单词,从而提高翻译的适用性。
完成下面两步后,将自动完成登录并继续当前操作。