谷歌DeepMind推出PaliGemma 2视觉语言模型,提供三种尺寸和分辨率,性能卓越。该模型结合了SigLIP-So400m图像编码器和Gemma 2 LLM,经过多项基准测试,超越了现有前沿模型。PaliGemma 2可生成详细图像描述,支持多种任务,且在CPU上运行时质量无显著差异。
PaliGemma 2是谷歌开发的先进视觉语言模型,具备图像和文本处理能力,支持多语言输入输出,表现优异于图像标注和视觉问答任务。该模型经过严格的数据过滤,确保安全和隐私,用户可通过NodeShift平台在GPU虚拟机上快速部署。
Google DeepMind推出的视觉语言模型PaliGemma 2系列包含九个不同参数和分辨率的预训练模型,适用于图像字幕和视觉问答等任务,具备灵活性和可扩展性,满足多样化用户需求。
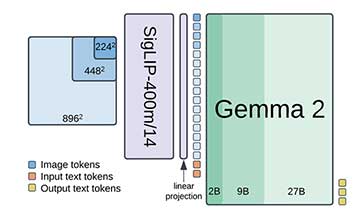
PaliGemma是一个开放的视觉语言模型,结合了SigLIP和Gemma-2B,旨在提升视觉-语言任务的性能。它由图像编码器、语言模型和线性层组成,经过多阶段预训练以优化表现。
本文介绍了清华大学的机器人控制大模型π0,该模型结合视觉、语言和动作数据,旨在提升机器人在多任务中的表现。通过预训练和微调,模型能够有效处理复杂物理任务,展现出高频灵巧控制能力。
PaliGemma是Google开发的多模态视觉语言模型,可对图片进行深入分析并提供有用的数据洞见。文章介绍了PaliGemma的环境搭建和演示代码,并强调了它在自动化客服、智能教育和内容创作等领域的应用潜力。
PaliGemma是Google开发的轻量级视觉语言模型,提供了三种可下载的模型类型:PT预训练模型、Mix通用模型和FT专用模型。每种模型有不同的参数和适用场景。
完成下面两步后,将自动完成登录并继续当前操作。