
Google DeepMind 发布 PaliGemma 2:全新开放式视觉语言模型系列(3B、10B 和 28B)
内容提要
Google DeepMind推出的视觉语言模型PaliGemma 2系列包含九个不同参数和分辨率的预训练模型,适用于图像字幕和视觉问答等任务,具备灵活性和可扩展性,满足多样化用户需求。
关键要点
-
视觉语言模型 (VLM) 在推广到不同任务方面面临重大挑战。
-
Google DeepMind 推出了 PaliGemma 2 系列,包含九个不同参数和分辨率的预训练模型。
-
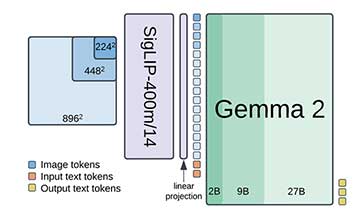
PaliGemma 2 支持 224×224、448×448 和 896×896 像素的分辨率,适用于多种用例。
-
模型在 DOCCI 数据集上进行了微调,提供更大的迁移学习和微调灵活性。
-
PaliGemma 2 结合了 SigLIP-So400m 视觉编码器和 Gemma 2 语言模型,分三个阶段进行训练。
-
在 30 多个传输任务上测试,表现出色,尤其是在图像字幕和视觉问答任务中。
-
模型越大、分辨率越高,通常性能越好,28B 变体提供最高性能。
-
提供不同规模和分辨率的模型,满足研究人员和开发人员的特定需求。
-
PaliGemma 2 在文本检测和 OCR 任务中取得了最高分,显示出精确度和召回率的提高。
-
PaliGemma 2 满足从资源受限场景到高性能研究任务的广泛应用需求,具有多功能性。
延伸解读
视觉语言模型的挑战与机遇
尽管视觉语言模型(VLM)在多个任务上取得了进展,但在处理不同类型输入数据时仍面临挑战。PaliGemma 2系列的推出,正是为了应对这些挑战,提供灵活的解决方案,适应从文档识别到图像字幕制作的多样化需求。
模型选择的灵活性
PaliGemma 2系列提供了多种参数和分辨率的模型,用户可以根据具体需求和计算资源选择合适的版本。这种灵活性使得研究人员和开发者能够在效率与准确性之间找到最佳平衡,满足不同应用场景的需求。
性能与资源的权衡
在选择PaliGemma 2的不同变体时,用户需考虑模型大小与计算资源的关系。虽然更大的模型通常性能更佳,但也需要更多的计算资源,因此在资源受限的环境中,选择合适的模型至关重要。
延伸问答
PaliGemma 2系列模型的参数大小有哪些?
PaliGemma 2系列模型的参数大小分别为30亿(3B)、100亿(10B)和280亿(28B)。
PaliGemma 2支持哪些分辨率?
PaliGemma 2支持224×224、448×448和896×896像素的分辨率。
PaliGemma 2在什么任务上表现出色?
PaliGemma 2在图像字幕和视觉问答任务上表现出色。
PaliGemma 2如何提高迁移学习和微调的灵活性?
PaliGemma 2是开放重量的,用户可以直接替代或升级原始模型,从而提供更大的迁移学习和微调灵活性。
PaliGemma 2的训练过程是怎样的?
PaliGemma 2结合了SigLIP-So400m视觉编码器和Gemma 2语言模型,分三个阶段进行训练,使用不同的图像分辨率。
PaliGemma 2在OCR任务中的表现如何?
PaliGemma 2在OCR任务中取得了最高分,显示出精确度和召回率的提高。
