
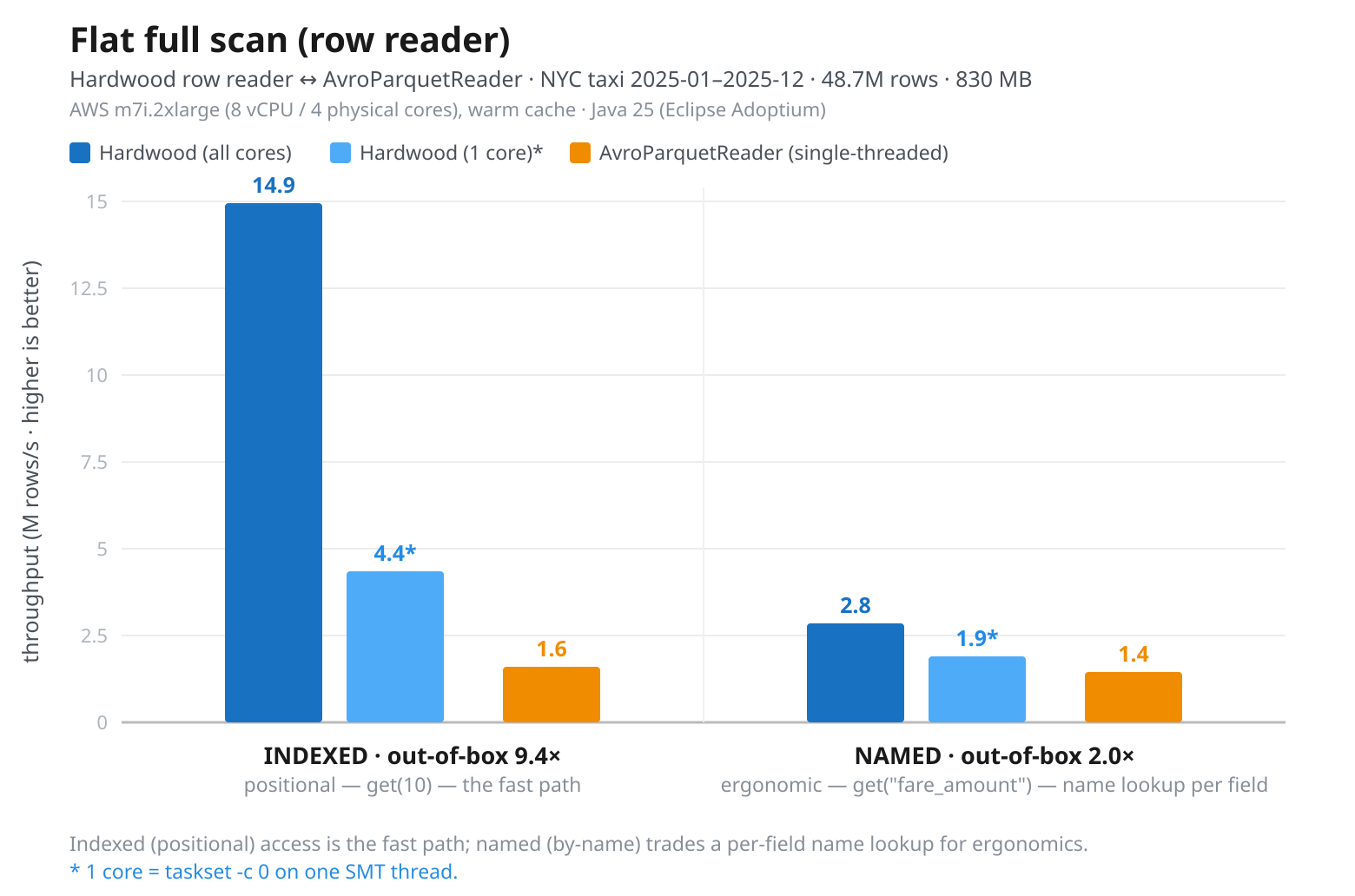
Hardwood 1.0:一个快速、轻量级的Apache Parquet读取器,适用于JVM
morling.dev -- Blog
·

第737期:Polars 1.41、电子邮件、优秀文档及更多内容(2026-06-02)
PyCoder’s Weekly
·

VARIANT支持,交互式Parquet文件TUI:Hardwood 1.0.0.Beta2发布
morling.dev -- Blog
·
VARIANT支持,交互式Parquet文件TUI:Hardwood 1.0.0.Beta2发布
morling.dev -- Blog
·


使用Python、Parquet和DuckDB构建现代数据分析架构
KDnuggets
·

AI/BI仪表板性能优化的十大最佳实践(第二部分)
Databricks
·
CSV、Parquet 和 Arrow:存储格式解析
KDnuggets
·

Parquet?什么是Parquet?
DEV Community
·

安全扩展:Cloudflare在全球服务健康指标和软件发布方面的策略
The Cloudflare Blog
·

使用Parquet文件处理大规模数据:优缺点
DEV Community
·

将文件上传至S3
DEV Community
·

使用DuckDB、Quarkus和Kotlin将Parquet文件转换为可查询的RESTful API
DEV Community
·

Parquet的两个版本
DEV Community
·

数据缩略语过载:ETL与ELT、数据湖与数据仓库、Parquet与CSV,以及更多
DEV Community
·

数据格式 - 如何及何时使用
DEV Community
·

测试
DEV Community
·
