
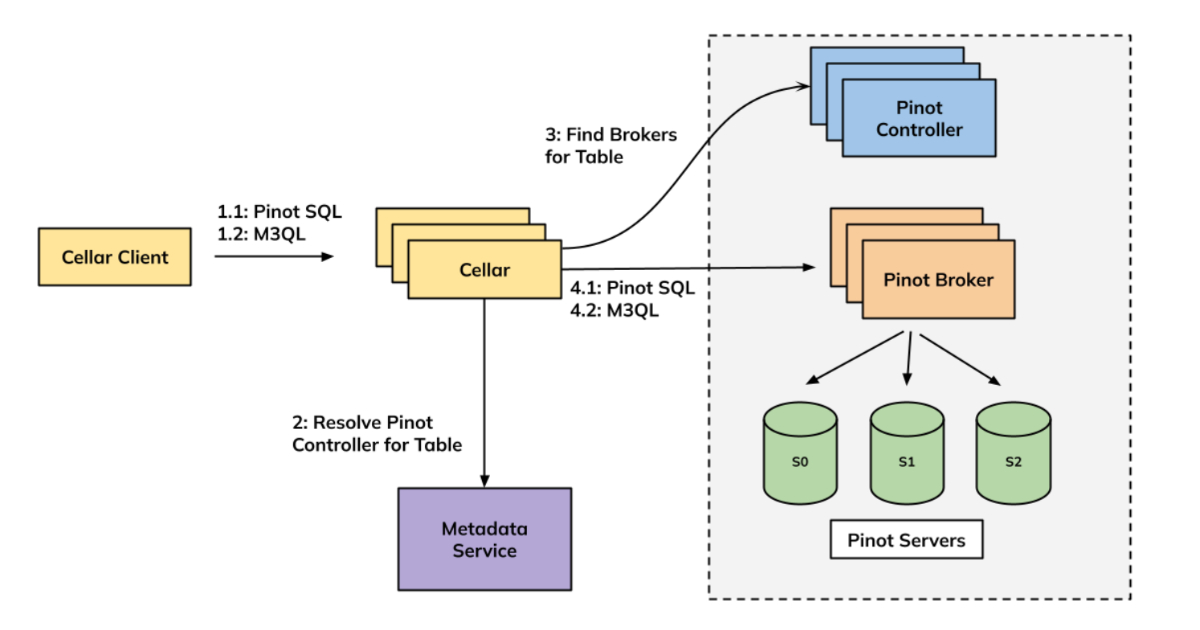
深入了解Uber的Pinot查询重构:简化层次结构与提升可观察性
InfoQ
·

Apache Pinot为列式数据带来实时分析
The New Stack
·
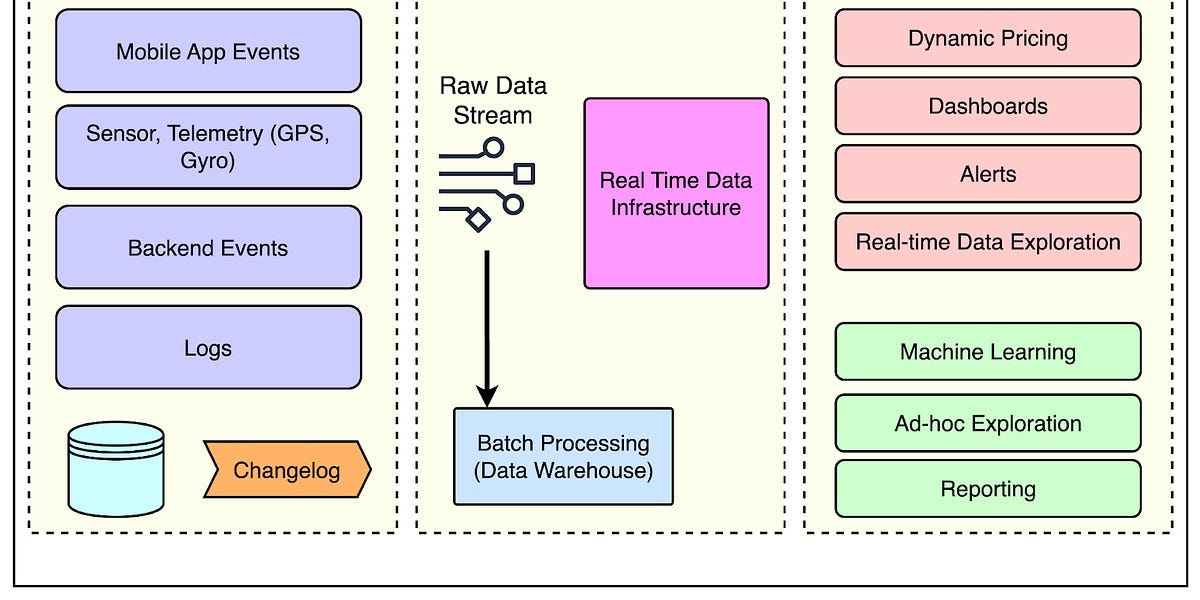
Uber如何管理PB级实时数据
ByteByteGo Newsletter
·
