
Uber如何管理PB级实时数据
内容提要
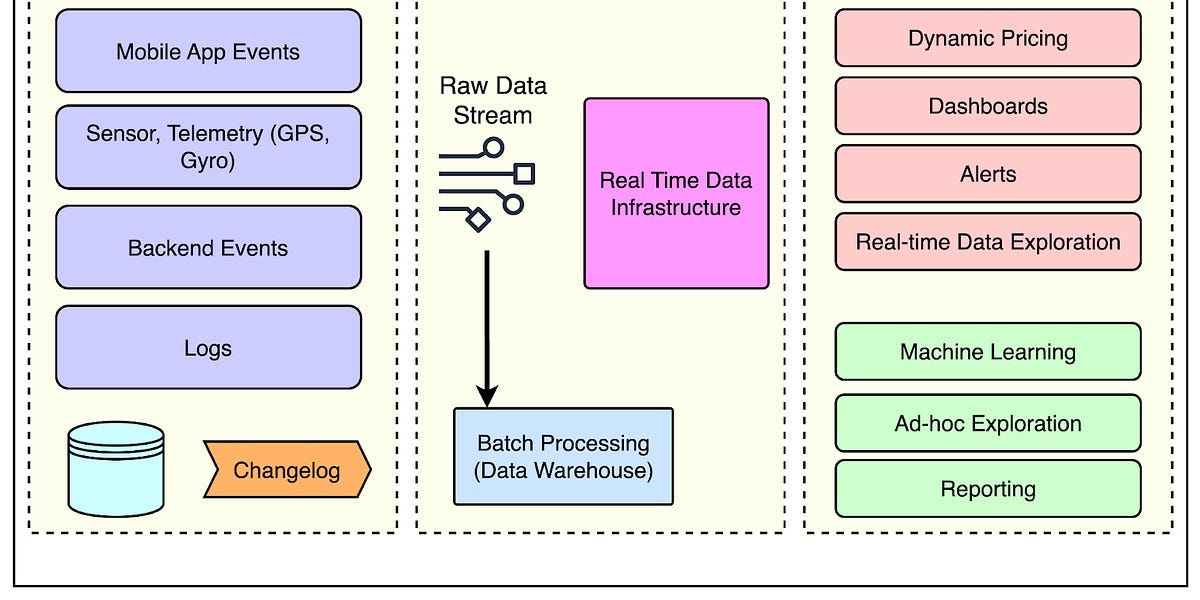
Uber的实时数据基础设施是其业务核心,每天处理大量数据。系统由消息平台、流处理和OLAP组成,确保数据快速分析。关键要求包括一致性、可用性、数据新鲜度、可扩展性和成本效率。Uber使用定制的开源技术如Kafka、Flink和Pinot,支持动态定价、UberEats管理和实时预测等功能。
关键要点
-
Uber的实时数据基础设施是其业务核心,每天处理大量数据。
-
Uber收集了PB级的数据,支持客户激励、欺诈检测和机器学习预测等功能。
-
系统由消息平台、流处理和OLAP组成,确保数据快速分析。
-
关键要求包括一致性、可用性、数据新鲜度、可扩展性和成本效率。
-
Uber使用定制的开源技术如Kafka、Flink和Pinot,满足其大规模数据需求。
-
Kafka用于数据流处理,支持数万亿条消息的传输。
-
Flink用于实时流处理,能够高效处理复杂工作负载。
-
Pinot用于实时OLAP,支持低延迟的数据分析。
-
Uber的实时数据基础设施支持动态定价、UberEats管理和实时预测等功能。
-
Uber采用了Active-Active和Active-Passive Kafka设置以确保高可用性和数据一致性。
-
Kappa+架构允许Uber在实时和历史数据处理之间无缝切换。
-
Uber强调开源技术的采用和系统的快速开发,以适应不断变化的业务需求。
-
自动化操作是Uber管理庞大数据基础设施的关键,减少了人工干预的需要。
-
Uber的成功在于结合开源解决方案与定制工程努力,以满足快速增长的数据驱动组织的需求。
延伸解读
实时数据基础设施的重要性
Uber的实时数据基础设施是其业务的核心,支持动态定价、UberEats管理等关键功能。随着用户和数据量的增加,保持系统的高可用性和低延迟变得尤为重要。用户在使用Uber服务时,几乎看不到延迟,这背后是复杂的技术架构和高效的数据处理策略。
开源技术的优势与挑战
Uber采用了Kafka、Flink和Pinot等开源技术,这为其数据处理提供了灵活性和可扩展性。然而,Uber也面临着将这些技术定制化以满足自身需求的挑战。开源技术的快速迭代和社区支持是其成功的关键,但同时也需要持续的工程投入来确保系统的稳定性和性能。
高可用性架构的实施
Uber通过Active-Active和Active-Passive Kafka设置来确保数据的一致性和高可用性。这种架构允许在一个区域出现故障时,系统能够迅速切换到其他区域,确保服务不中断。对于依赖实时数据的功能,如动态定价,这种冗余设计至关重要。
延伸问答
Uber的实时数据基础设施有哪些关键组成部分?
Uber的实时数据基础设施由消息平台、流处理和OLAP组成。
Uber如何确保其数据的一致性和可用性?
Uber采用Active-Active和Active-Passive Kafka设置,以确保高可用性和数据一致性。
Uber使用哪些开源技术来处理实时数据?
Uber使用Kafka、Flink和Pinot等定制的开源技术来处理实时数据。
Uber的实时数据基础设施如何支持动态定价?
Uber通过Kafka和Flink的数据管道实时处理乘车请求和司机可用性,从而实现动态定价。
Uber如何处理历史数据的再处理?
Uber使用Kappa+架构,允许在实时和历史数据处理之间无缝切换,支持历史数据的再处理。
Uber在实时数据处理方面面临哪些挑战?
Uber需要扩展系统以处理更多数据,支持新用例,并确保数据新鲜度和低延迟。
