制造业数字化转型的核心系统包括ERP(企业资源计划)、PLM(产品生命周期管理)和MES(制造执行系统)。ERP负责订单和库存管理,PLM管理产品图纸和BOM,MES执行生产计划和数据采集。这三者相互连接,确保数据共享,消除信息孤岛,为数字化转型奠定基础。
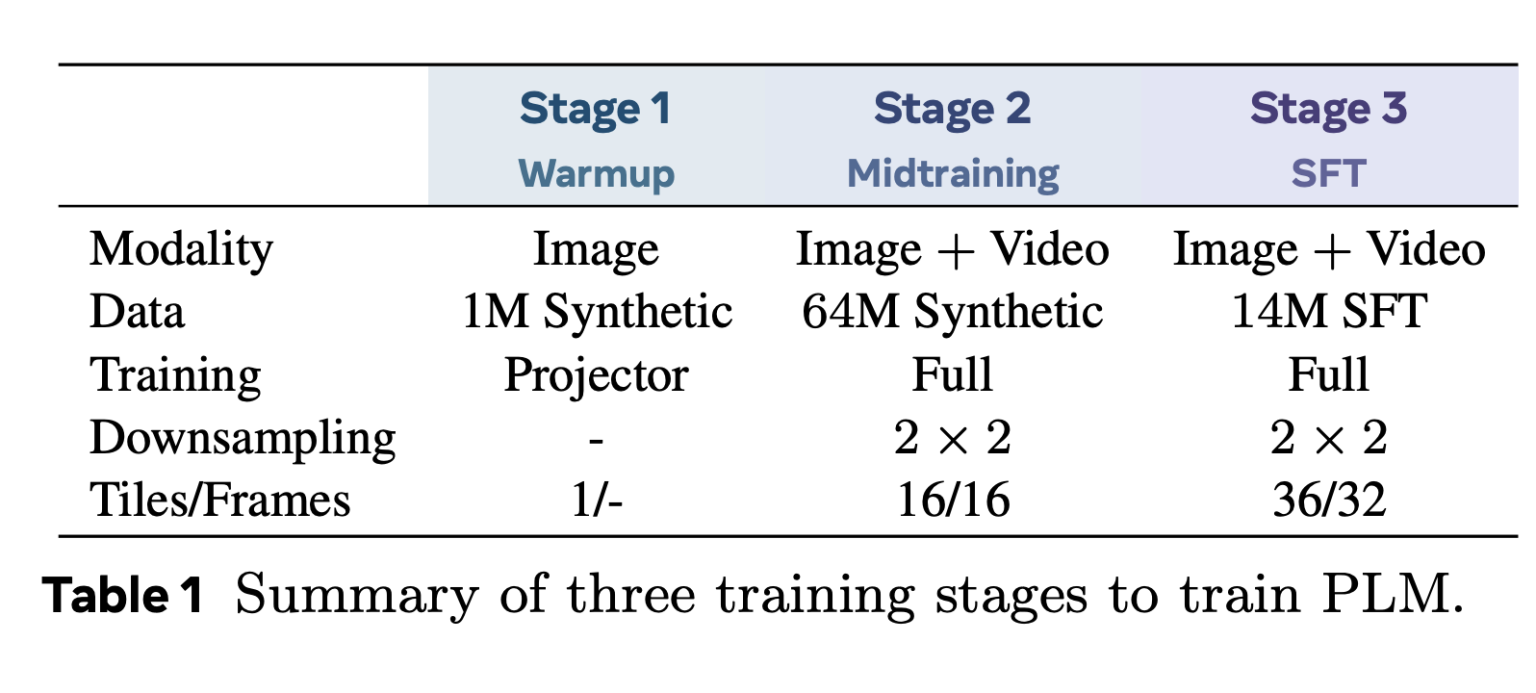
Meta AI推出了感知语言模型(PLM),这是一个开放且可复现的视觉语言建模框架,支持图像和视频输入。PLM通过合成数据和人工标记数据进行训练,强调透明性和可评估性,集成了视觉编码器和不同参数的语言解码器,采用多阶段训练流程。PLM发布了两个高质量视频数据集,支持细粒度视频理解,并在多个基准测试中表现优异,推动了多模态人工智能研究。
本研究解决了蛋白质语言模型(PLMs)在生物解释和可操作性方面的局限性,提出了一种可解释的适配器层PLM-eXplain(PLM-X),通过将PLM嵌入划分为基于生化特征的可解释子空间和保留模型预测能力的残差子空间来实现。研究表明,PLM-X在多个蛋白质分类任务中有效,能够在不牺牲准确性的情况下,提供对模型决策的生物学解释,从而为计算生物学的深度学习模型与生物学洞察之间搭建桥梁。
PLM团队开发了一种新型边缘设备语言模型,结合MLA注意力机制和ReLU²激活函数,优化了计算效率和内存使用。该模型在多项任务中表现优异,适配多种硬件,展现出高效、低延迟的性能,推动了边缘设备AI应用的发展。
浙江大学研究人员开发了基于蛋白质语言模型的自动进化平台PLMeAE,结合机器学习与自动化生物工厂,显著提高了蛋白质工程的速度和准确性,优化了设计与测试流程,推动了工业应用的发展。
蛋白质的功能与其三维结构密切相关。科学家们开发了预训练的蛋白质语言模型ProSST,结合结构信息以提高预测准确性。ProSST在1,880万蛋白质结构数据上预训练,采用解耦注意力机制,显著提升了热稳定性和金属离子结合等任务的预测性能,成为蛋白质研究的重要工具。
本研究提出了多种基于扩散模型的语言生成方法,如Diffusion-LM、DiffusionBERT和EDLM,显著提升了文本生成的质量和速度。实验结果显示,这些模型在细粒度控制任务和基准测试中表现优异,尤其在减少采样步骤时性能提升明显。
在「Meet AI4S」直播中,周子宜博士介绍了蛋白质语言模型(PLM)在蛋白质工程中的应用。PLM通过建模蛋白质序列的共进化信息来预测突变的适应性,并生成蛋白质。研究重点包括检索增强型、多模态PLM和小样本学习方法FSFP。FSFP通过排序学习、LoRA和元学习提升性能,适用于不同PLM。未来方向包括AI辅助定向进化中的主动学习策略。
本研究提出了一种扩展多语言BERT的方法用于命名实体识别(NER)实验,结果显示对已包含语言的F1值提高6%,对新语言提高23%。该方法结合知识蒸馏和一致性训练,展示了在低资源语言上通过少量标记样本实现合理性能的潜力,具有重要的多语言应用开发意义。
本文介绍了多种基于预训练语言模型的零样本学习方法,如SunGen、ZeroGen和ProGen,旨在自动生成高质量数据以提升模型性能。这些方法在文本分类、问答和自然语言推理等任务中表现优异,有效提高了小型模型的泛化能力和推理效率。
本文介绍了ElitePLM对预训练语言模型进行大规模实证研究,设计了四个评估维度来衡量PLMs的能力。实验结果显示PLMs在不同测试中表现出色,微调对数据敏感,具有可转移性。该论文可指导未来工作选择和设计特定任务的PLMs。
通过优化传统技术,实现了改进的无监督PCA技术,解决了日志数据中未知事件问题,提升了表示效果。研究比较了七种异常检测方法,结果显示优化PCA在数据和资源效率上与先进DL方法相似,证明了传统技术的适应性和优势。
本研究提出了一种名为Mix Prompt Tuning (MPT)的半监督学习方法,通过多个低资源科学分类任务的实验证实了该方法的有效性。与微调算法相比,MPT平均提高了5%的Macro-F1分数。MPT是一种通用方法,可轻松应用于其他低资源科学分类任务。
本文介绍了制造行业的五大核心系统MES、ERP、WMS、PLM和SCADA之间的关系,它们分别用于订单管理、产品制造、仓库管理、产品管理和设备管理。这些系统的集成形成工厂的大脑,驱动工厂的订单执行和产品开发工作。
完成下面两步后,将自动完成登录并继续当前操作。