原力灵机推出的DW0.5具身世界模型,结合DFOL2.0框架,降低了60%的真机数据需求。DW0.5通过模拟动作后果与价值反馈,提升机器人在复杂环境中的学习能力,支持多模态输入,增强训练效率和成本效益。该模型在多个基准测试中表现优异,已实现闭环流程,未来将应用于具身智能领域。
本文介绍了一种名为“Focus-Then-Contact”(FTC)的强化学习方法,旨在提高机器人在接触密集任务中的学习效率。FTC结合了残差强化学习和基于关键帧的可供性引导奖励,通过人类干预优化策略,提升了机器人在真实环境中的操作能力,有效减少了稀疏奖励带来的学习困难,促进了更高效的在线学习。
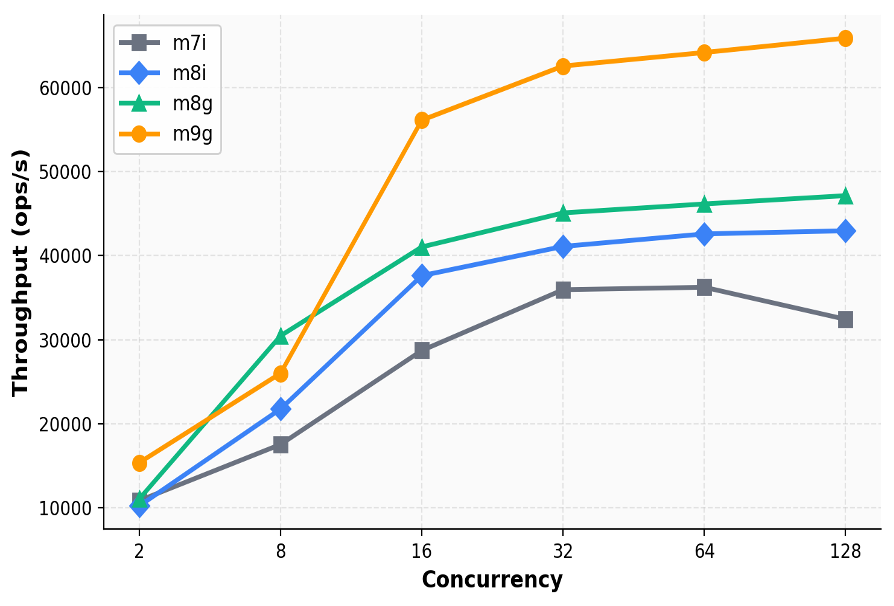
本文分析了基于Graviton的Agentic RL沙盒层的成本优化,指出使用Graviton5的m9g实例可将沙盒层成本降低约41%。沙盒层在Agentic RL训练中是CPU密集型,与GPU训练并行,影响整体训练效率。基准测试显示,Graviton在处理高并发请求时性能显著优于Intel实例,整体迁移至Graviton可有效降低训练成本并提升性能。
AReaL 2.0 版本发布,旨在提升智能体在真实业务中的持续学习能力。通过记录任务交互,智能体能够在安全环境中优化模型,适应复杂变化的任务。该系统引入数据代理机制,确保数据安全管理。AReaL 项目由蚂蚁集团等发起,未来将继续推动智能体生态发展。
在具身智能领域,视觉-语言-动作(VLA)模型面临模仿学习导致的误差累积问题。华为云的HIL-ResRL方法通过人机协同和残差策略,提高了机器人在真实环境中的任务成功率,实验成功率超过95%。该方法无需重训练,适用于多种工业任务,并通过触觉反馈显著提高精度,展示了快速部署的潜力。
HIL-ResRL是一种即插即用的VLA工具,经过1小时微调后成功率超过95%。该技术在提升机器学习模型应用效率方面具有重要意义。
本文讨论了QGF(Q引导流)方法在强化学习中的应用,解决了扩散和流策略训练不稳定性的问题。通过预训练参考策略和价值函数,QGF利用价值梯度引导生成高价值动作,避免复杂的反向传播,从而提升策略的稳定性和可扩展性。
微软 AI 团队提出了「爬山机器」框架,并训练了参数达到 1T 的 MoE 模型 MAI-Thinking-1。该模型通过自适应熵控制的强化学习,在无第三方数据的情况下实现了长期稳定的性能增长,并在多个基准测试中取得领先水平。
TACK 是 AI Laboratory for Molecular Engineering 于 2026 年发布的一个标准化知识库数据集与基准测试集,旨在解决现有 PROTAC 机器学习基准中数据稀缺、缺乏严格评估及覆盖范围有限的问题,广泛应用于 PROTAC...
后训练是调整预训练模型以实现特定目标的方法,包括预训练、监督微调、奖励建模、策略优化和评测。风格对齐关注表达方式,能力激发关注任务成功率。RLHF通过人类偏好优化助手行为,DPO简化为离线分类损失,RLVR通过可验证奖励提升推理能力。
PRISM团队的研究表明,监督微调(SFT)并未促进强化学习(RL),反而可能导致模型性能下降。研究提出了SFT、分布对齐和RL的三阶段流程,强调在多模态模型中,SFT引入的分布偏差需要单独处理。通过对抗博弈对齐分布,PRISM显著提升了模型在推理任务上的表现,修复了SFT的副作用。
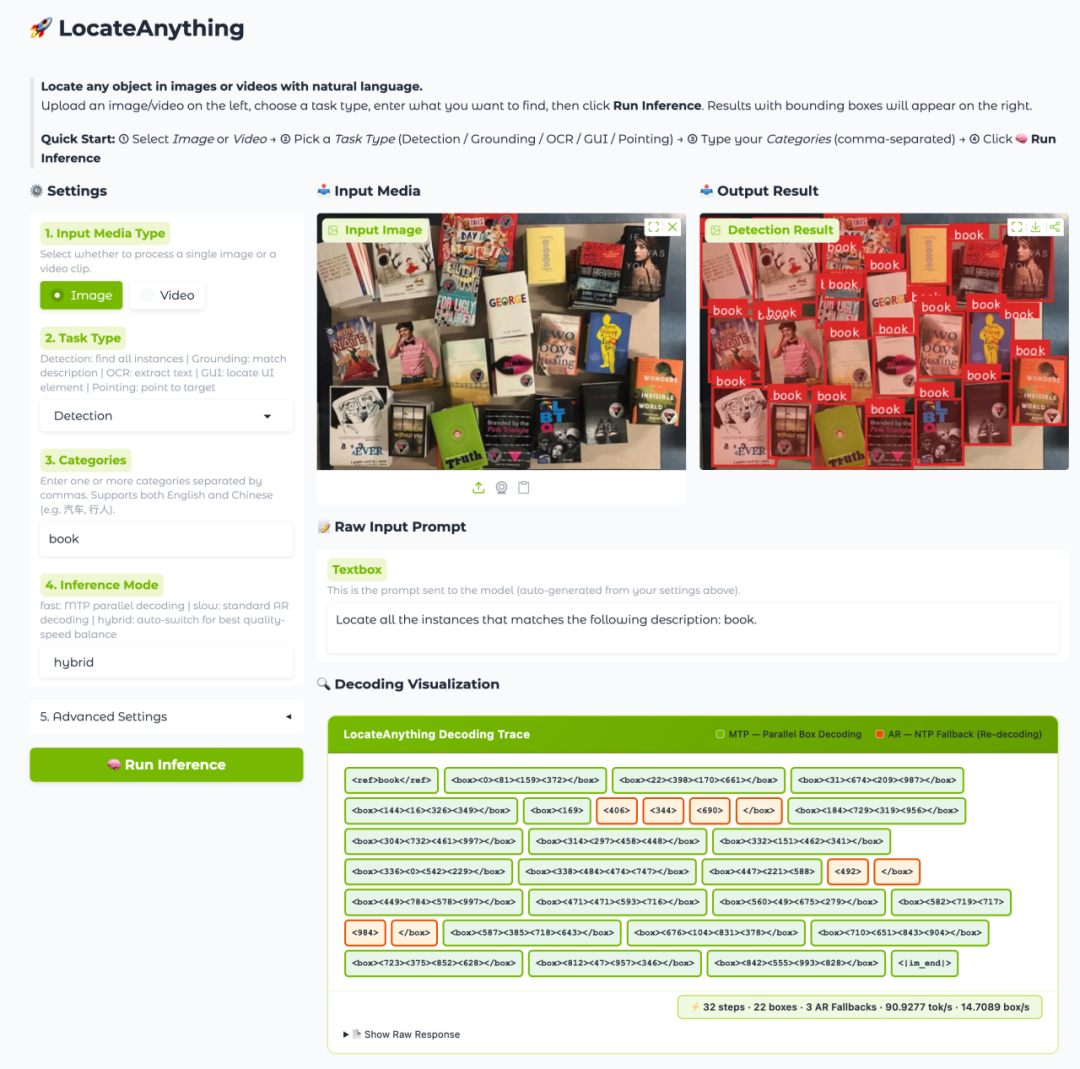
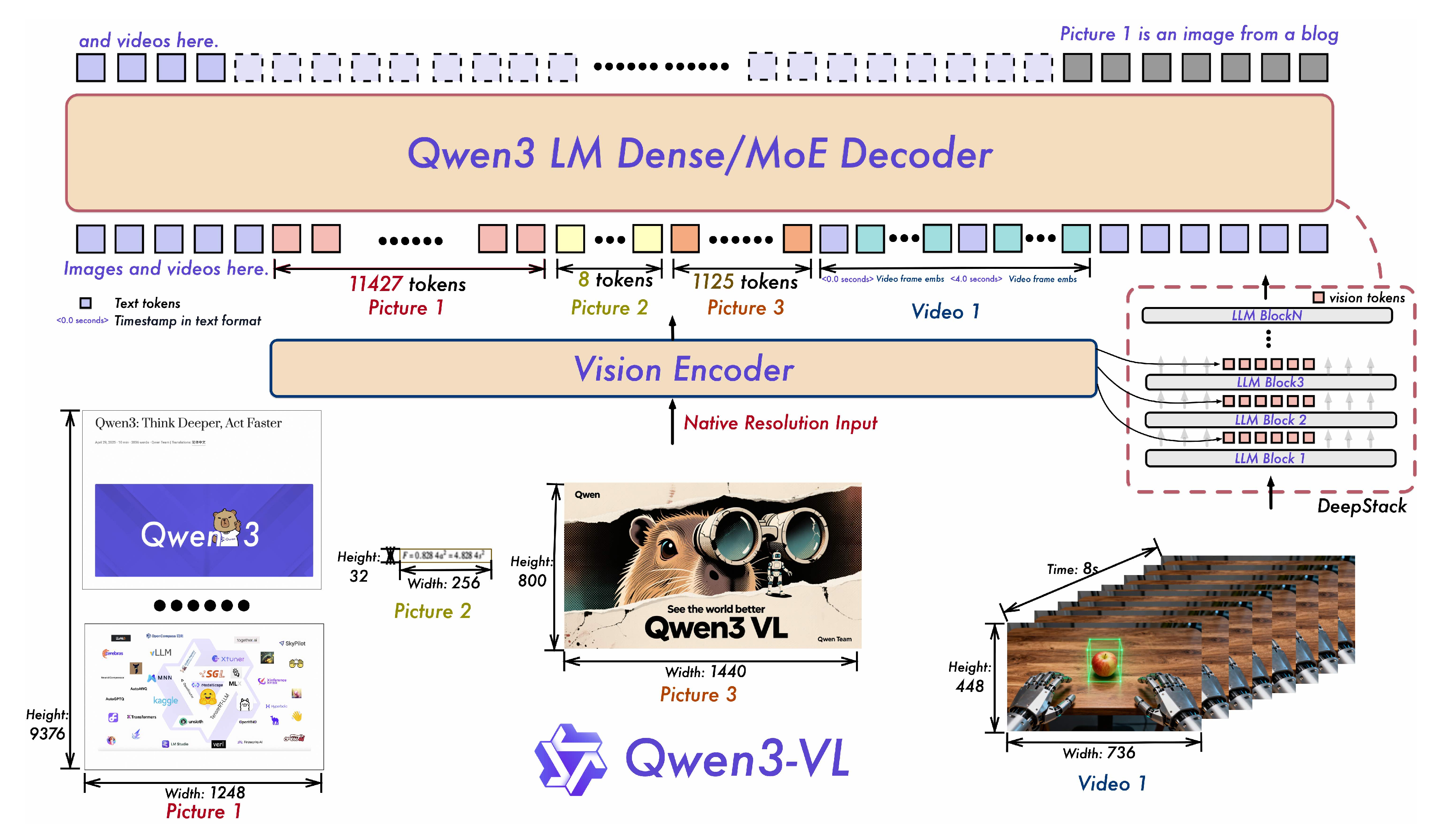
Qwen系列模型最新升级为Qwen3-VL,在视觉理解和视频处理方面有显著提升。引入多维旋转位置编码(MRoPE)和DeepStack技术,增强了对复杂场景的推理能力,支持长文档和长视频处理,具备更高的上下文长度和精确的时间定位能力,推动多模态理解的进步。
本文讨论了Mooncake Store在统一内存池、local master和softpin语义方面的演进,强调了主动释放lease和故障注入的重要性,以提高系统性能和稳定性。整体设计旨在应对高并发场景下的挑战。
本文讨论了在真实世界中部署通用机器人策略的挑战,提出了一种名为“部署中学习”(LWD)的框架,通过车队规模的离线到在线强化学习(RL)实现策略的持续改进。该方法结合离线数据和在线交互,利用多样化的部署经验,优化策略以适应新任务和环境。作者提出的分布式隐式价值学习(DIVL)和带有伴随匹配的Q学习(QAM)技术,旨在提高策略的稳定性和泛化能力,实现高效的后训练。
本文探讨了觉-语言-动作(VLA)模型在机器人学习中的应用,提出了一种视频生成式价值模型(ViVa),通过预测未来状态来改进价值估计。ViVa结合预训练的视频生成模型、当前观测和本体感知,评估任务进展,提升机器人在复杂环境中的操作能力。研究表明,该方法在真实世界任务中表现优越,能够有效跟踪任务进度并处理新颖物体。
刘壮和陈丹琦团队推出了开源视觉推理强化学习框架Vero,支持多种视觉任务,克服了单一任务训练的局限性。Vero通过600K高质量样本和任务路由奖励机制,在多项基准测试中超越现有模型,展示了广泛数据对视觉推理的促进作用。
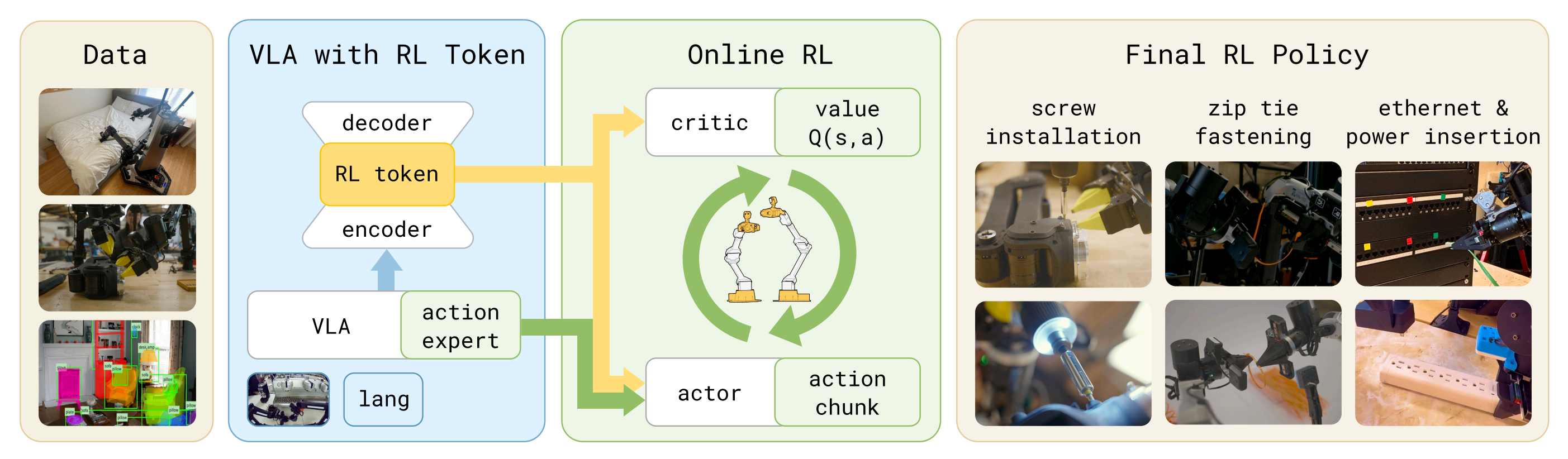
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
本文介绍了Ψ0模型,该模型结合大规模人类视频数据与真实机器人数据,训练出一种用于类人机器人灵巧运动的视觉-语言动作模型,能够有效提取运动先验,实现复杂的全身控制。
本文探讨了一种双执行体强化学习框架,结合人类反馈优化视觉-语言-动作(VLA)模型。通过“对话与微调”机制,机器人在长时域操作中实现高效学习,成功率达到100%。该方法在多任务设置中展现出良好的样本效率和训练稳定性,适用于复杂的机器人操作任务。
本文讨论了在 Mooncake 接入 RL 中的 local master 和统一内存池设计,通过整合数据平面减少数据拷贝,提高效率。提出了统一的内存分配、元数据管理和生命周期管理,确保数据高效访问和管理。强调 AI 在代码实现中的辅助作用,认为 Rust 语言更适合此类开发。
完成下面两步后,将自动完成登录并继续当前操作。