微软的VibeVoice语音生成模型因其强大功能被下架,后加水印后免费开源。该模型能够克隆声音、生成90分钟对话、实时响应,支持多语言并可本地运行。尽管有安全控制,仍需警惕深度伪造风险。VibeVoice将语音AI提升为内容生成系统,为开发者带来新机遇。
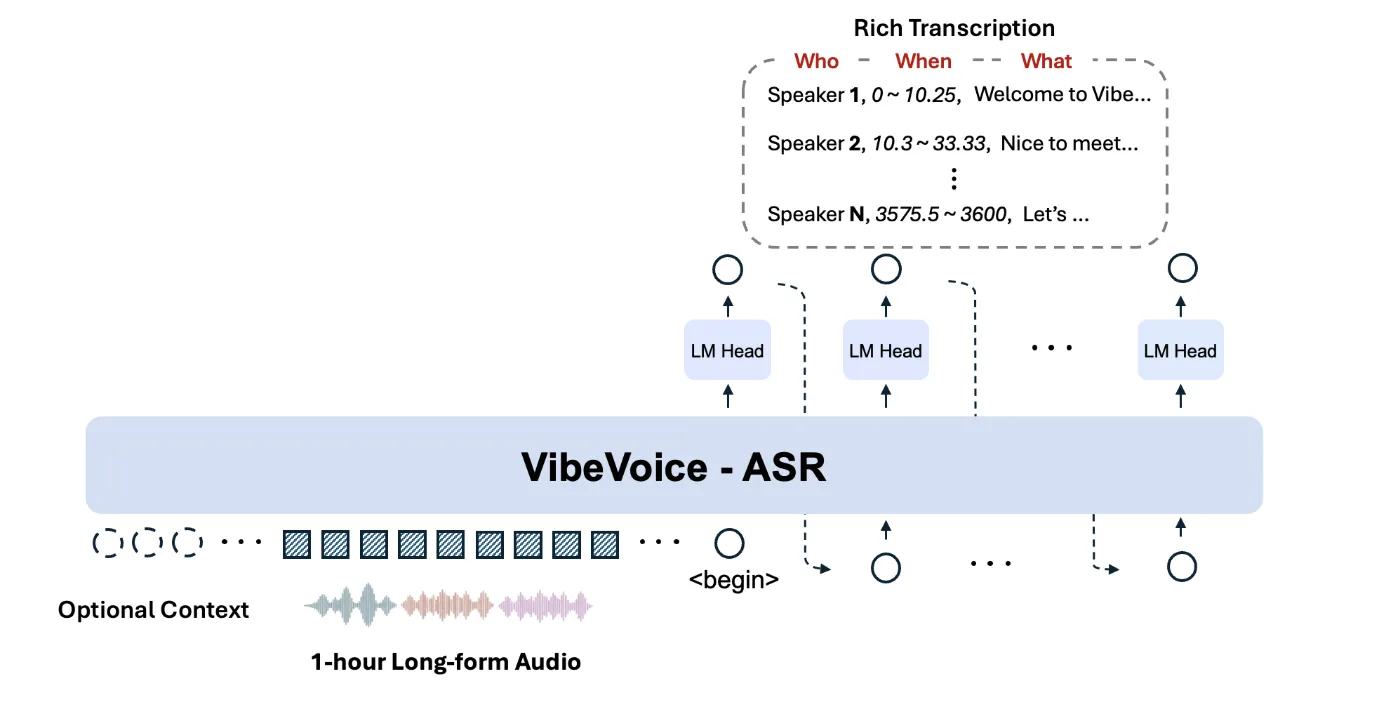
微软推出了VibeVoice-ASR,一个开源的语音转文本模型,支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。该模型允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
微软开源的VibeVoice项目能够生成最长90分钟的自然多人对话音频,支持最多4个说话人,突破传统TTS限制,兼容中英文及多语言合成,适合播客和教育内容制作。
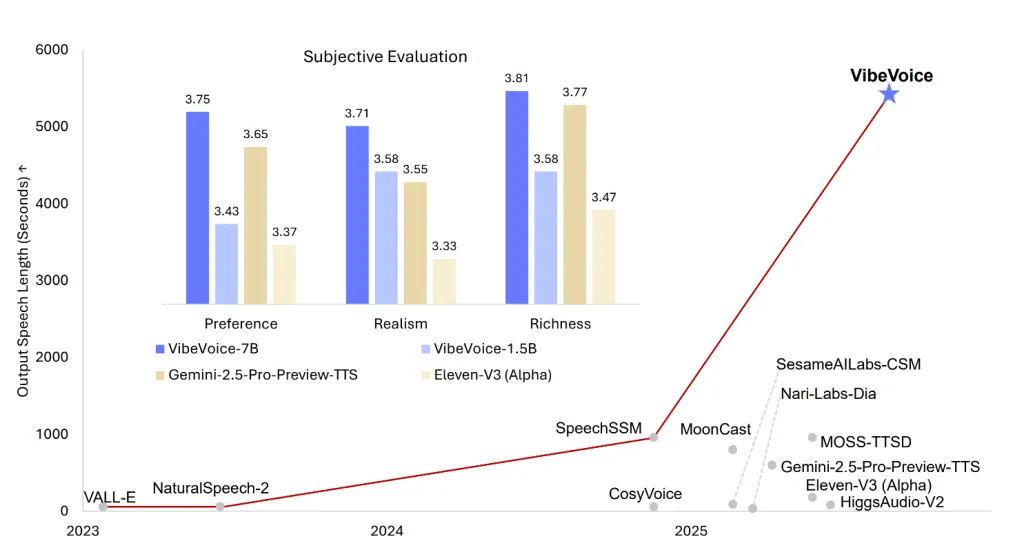
微软开源的VibeVoice是一种新型文本转语音(TTS)合成技术,能够生成高保真、多说话人的长语音。该技术采用下一token扩散方法,显著提高了长序列处理的效率和音频质量,支持最多4名说话人的对话,表现超越现有模型。用户可通过HyperAI官网体验实时语音合成服务。
本文介绍了如何在Google Colab上使用微软的开源文本转语音模型VibeVoice,设置高级对话AI并解决常见问题。VibeVoice能够生成自然且富有表现力的多说话人音频,适合播客和对话。文章详细描述了从克隆代码库到运行推理的步骤,并提供故障排除建议。
微软开源的VibeVoice-1.5B模型在TTS领域备受关注,能够生成90分钟的高自然度语音,支持4位说话者。其创新点在于双Tokenizer架构和扩散解码技术,MOS评分达到4.5。该模型主要面向科研和开发者,目前仅支持中英文,强调研究用途以防滥用。
微软的VibeVoice-1.5B是开源文本转语音技术的重大进展,支持长达90分钟的多说话人音频生成,具备跨语言和歌唱合成能力,采用流式架构,强调情感表现,适合播客和对话场景。
完成下面两步后,将自动完成登录并继续当前操作。