Introduction Vision Language Models (VLMs) are crucial for bridging the gap between visual and textual data by combining image and language understanding. Some important VLMs’ use cases are: VLMs...
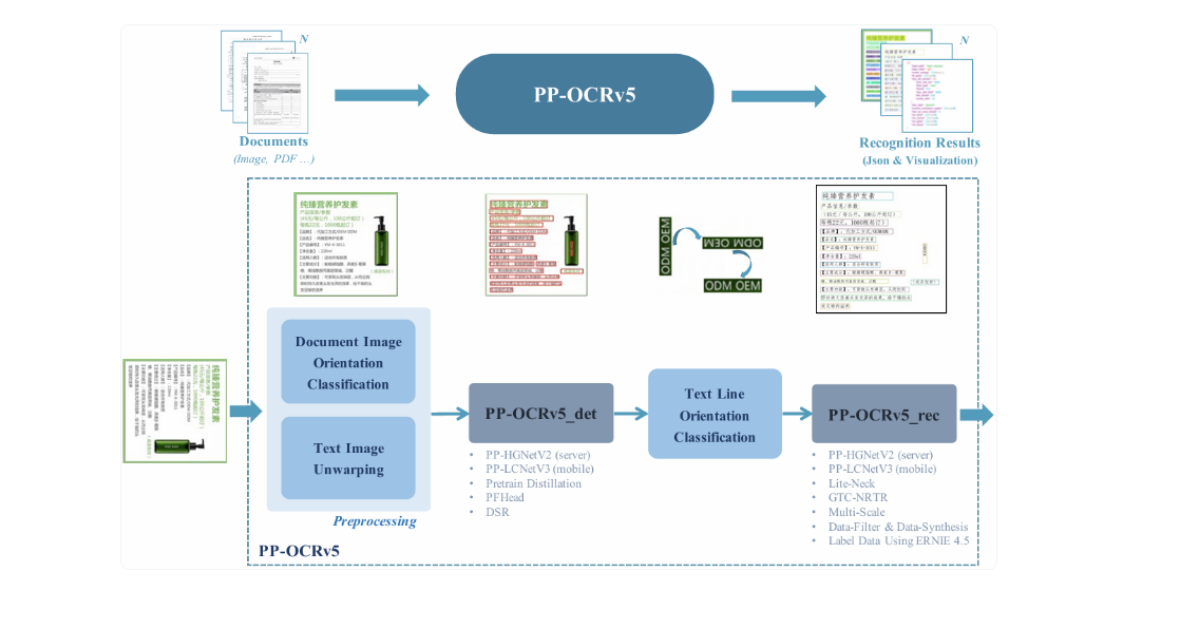
百度在Hugging Face发布了PP-OCRv5,这是一种高效的光学字符识别模型,专注于文本识别,支持多语言,适合边缘部署。尽管对其多语言能力有疑虑,但在手写和印刷文本的基准测试中表现优异。
本研究评估了三种视觉语言模型(RAD-DINO、CheXagent 和 BiomedCLIP)在胸部X光片气胸和心脏肥大任务中的表现。结果表明,RAD-DINO在分割任务中表现优异,而CheXagent在分类上更具优势。结合全局和局部特征的自定义模型显著提升了所有模型的性能,为选择基础模型提供了实用指导。
本文提出VLMGuard-R1框架,通过多模态推理驱动的提示重写方法,解决视觉-语言模型(VLM)与安全标准对齐的挑战。研究表明,该框架在多项基准测试中显著提升安全性,尤其在SIUO基准上实现43.59%的安全性提高,展现出重要的安全防护潜力。
本研究解决了传统《星际争霸II》框架与人类游戏体验之间的感知差异问题。通过引入VLM-Attention环境,结合RGB视觉输入和自然语言观察,使人工智能代理的决策更加符合人类的认知过程。实验表明,基于VLM的代理能够在没有明确训练的情况下执行复杂战术,表现与传统的多智能体强化学习方法相当,从而推动了多模态游戏AI的研究进展。
该研究介绍了一种新的交叉领域语义分割方法,利用视觉语言模型重新标记目标领域中的新类别。该方法在基准测试中表现良好,并与领域自适应方法相结合时展现出协同效应。
我们提出了一种方法,通过提供清晰且可定位的概念级解释,改善大规模预训练视觉语言模型对细粒度概念的理解,并且证明这种改进有助于降低模型对虚假相关性的依赖,进而提高预测准确性。
研究人员提出了一种名为移动 VLA 的导航策略,结合了视觉语言模型和拓扑图,能够理解多模式指令并进行有用的导航。在真实世界环境中的评估中,移动 VLA 在多模式指令情况下表现出高的成功率。
MobileVLM是专为移动设备设计的多模式视觉语言模型,性能与更大模型相当。在高通骁龙888 CPU和NVIDIA Jeston Orin GPU上,MobileVLM的推断速度分别为21.5个token和65.3个token每秒。
研究者构建了一个多模态评估集ChartX,包括18种图表类型、7种图表任务、22个学科领域和高质量的图表数据。他们开发了一个新的视角ChartVLM来处理多模态任务,并在ChartX评估集上进行了实验证明ChartVLM在图表相关能力上超越了通用的大模型,达到了与GPT-4V可比较的结果。研究者相信这项研究可以为创建更全面的图表评估集和开发更可解释的多模态模型方面的进一步探索铺平道路。
研究人员提出了一种新的方法来初始化实体强化学习策略,利用基于视觉语言模型的通用世界知识和可索引知识。他们在Minecraft和Habitat任务中评估了该方法,并发现基于通用VLMs提取的嵌入的训练策略表现更好。这项研究有望提高强化学习效果。
研究者提出了一种渐进式流水线和基准测试方法,发现现有视觉语言模型在细粒度理解方面表现不佳。他们提出了一种简单有效的优化方法,并验证了其在其他基准测试中的可迁移性。
研究人员提出了一种基于视觉语言模型的强化学习方法,通过在Minecraft和Habitat中的任务中评估,发现该方法表现更好。它优于其他策略、遵循指令的方法和特定领域的嵌入方法。
DetPro是一种新的开放词汇物体检测方法,通过学习基于预训练的视觉-语言模型的连续提示表示来实现。DetPro与ViLD对象检测器组合使用,在多个数据集上的实验结果显示DetPro优于基线ViLD。
我们提出了一种方法来边际化通过VLM查询变化的任何因素,利用采样响应的VLM分数。我们展示了这种概率整合可以在摘要中胜过语言模型,避免了在响应之间存在对比细节时的幻觉。此外,我们展示了聚合注释对于Prompt-Chaining是有用的;它们有助于改进下游VLM的预测,例如当在提示中将对象类型指定为辅助输入时,提高了对物体材料的预测质量。利用这些评估,我们展示了VLM可以在大规模Objaverse数据集上接近人工验证的类型和材料注释的质量,而无需额外的训练或上下文学习。
完成下面两步后,将自动完成登录并继续当前操作。