


现在可以使用SANA 4K模型在8GB VRAM以下生成16百万像素(4096x4096)原始图像及更多
DEV Community
·

最佳开源图像转视频模型CogVideoX1.5-5B-I2V,表现相当不错,并针对低VRAM进行了优化
DEV Community
·

Kohya对FLUX LoRA(4GB GPU)和DreamBooth / 微调(6GB GPU)训练进行了重大改进
DEV Community
·
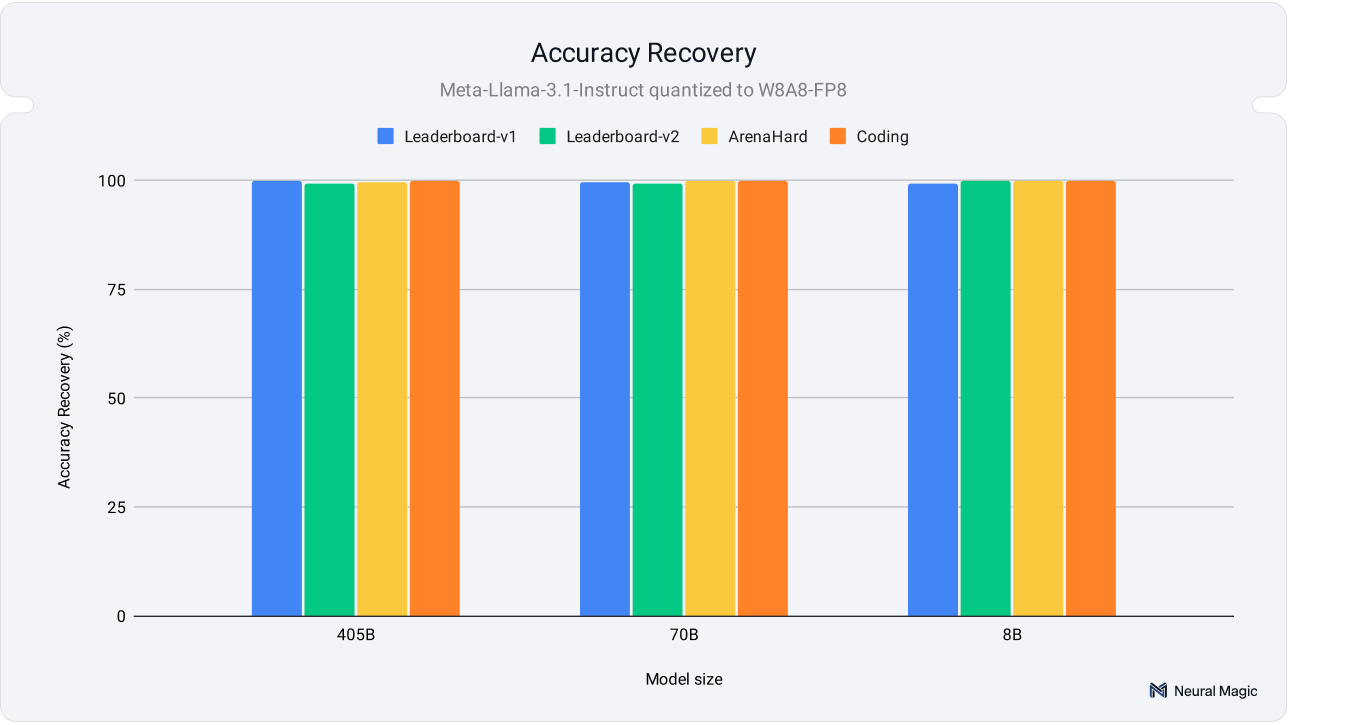
模型量化对模型精度影响的研究
编译程序
·
llama.cpp:CPU与GPU、共享VRAM与推理速度
DEV Community
·
