
模型量化对模型精度影响的研究
内容提要
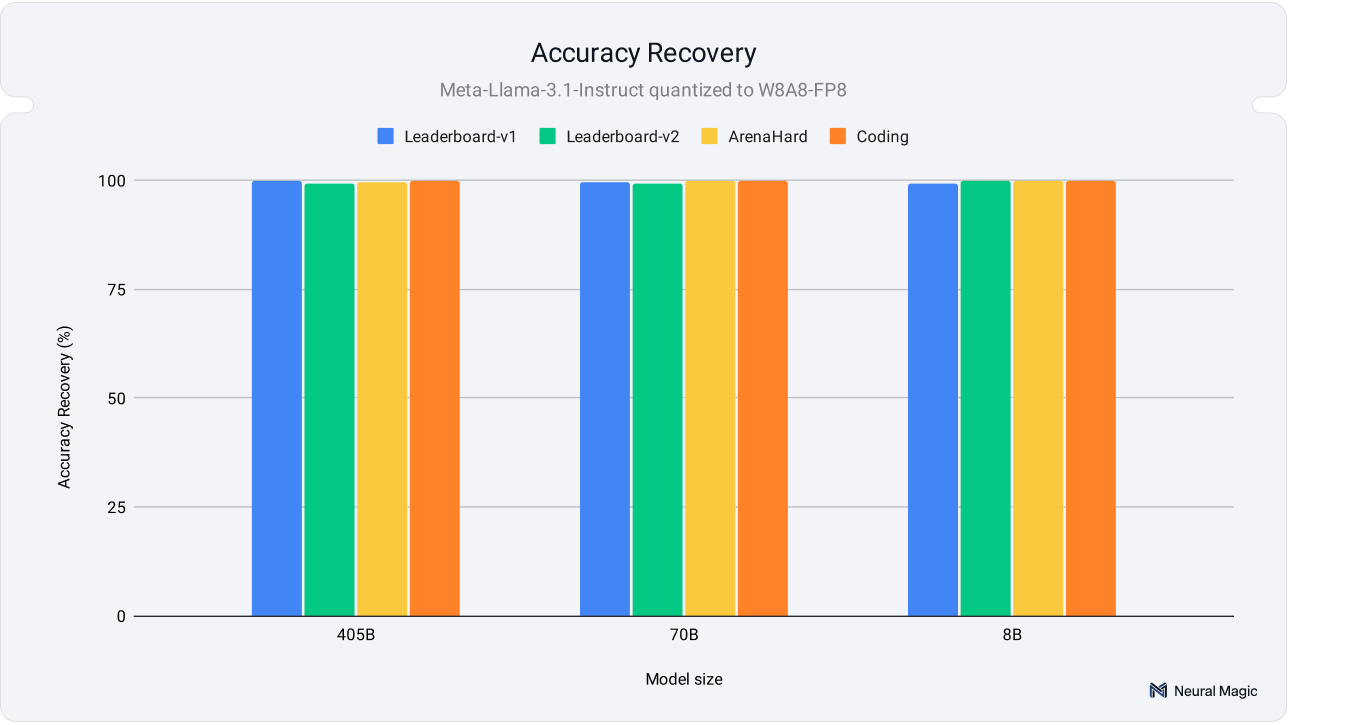
模型量化(如8bit或4bit)显著降低计算成本并加速推理。Neural Magic的研究表明,量化模型与全精度模型在准确性上差异不大,尤其是大模型(如70b、405b)保持98%以上的性能。尽管小模型(如8b)准确性波动较大,但仍能保持核心语义和结构一致性。量化不仅节省VRAM,还提升推理速度。
关键要点
-
模型量化(如8bit或4bit)显著降低计算成本并加速推理。
-
量化模型与全精度模型在准确性上差异不大,尤其是大模型(如70b、405b)保持98%以上的性能。
-
小模型(如8b)准确性波动较大,但仍能保持核心语义和结构一致性。
-
量化不仅节省VRAM,还提升推理速度。
延伸解读
量化模型的准确性与应用场景
量化模型在准确性上与全精度模型差异不大,尤其是大型模型(如70b、405b)保持98%以上的性能。这意味着在实际应用中,开发者可以选择量化模型以降低计算成本,而不必过于担心准确性损失。尤其在需要快速推理的场景中,量化模型的优势更加明显。
小模型的准确性波动
尽管小模型(如8b)在量化后准确性波动较大,但仍能保持核心语义和结构一致性。这提示开发者在选择模型时需考虑任务的复杂性和对准确性的要求,尤其是在对输出质量有较高期望的应用中,可能需要谨慎使用小模型。
基准测试的重要性
Neural Magic的研究通过多种基准测试评估量化模型的性能,强调了学术基准与真实世界基准的不同。学术基准适合结构化任务,而真实世界基准更能反映模型在实际应用中的表现。开发者在评估模型时,应关注不同基准的适用性,以选择最符合需求的模型。
延伸问答
模型量化的主要优点是什么?
模型量化显著降低计算成本并加速推理,同时节省VRAM。
量化模型与全精度模型的准确性差异如何?
量化模型与全精度模型在准确性上差异不大,尤其是大模型保持98%以上的性能。
小模型在量化后表现如何?
小模型(如8b)准确性波动较大,但仍能保持核心语义和结构一致性。
Neural Magic的研究结果是什么?
Neural Magic的研究表明,量化模型与全精度模型没有明显的差异,尤其在大模型上。
量化模型的测试方法有哪些?
测试方法包括学术基准测试和真实世界基准测试,评估模型在不同场景下的表现。
量化模型如何影响推理速度?
量化模型能够显著提升推理速度。
