

有效的机器学习模型Python内存优化十大技巧
DEV Community
·
在PyTorch模型中优化内存使用
MachineLearningMastery.com
·

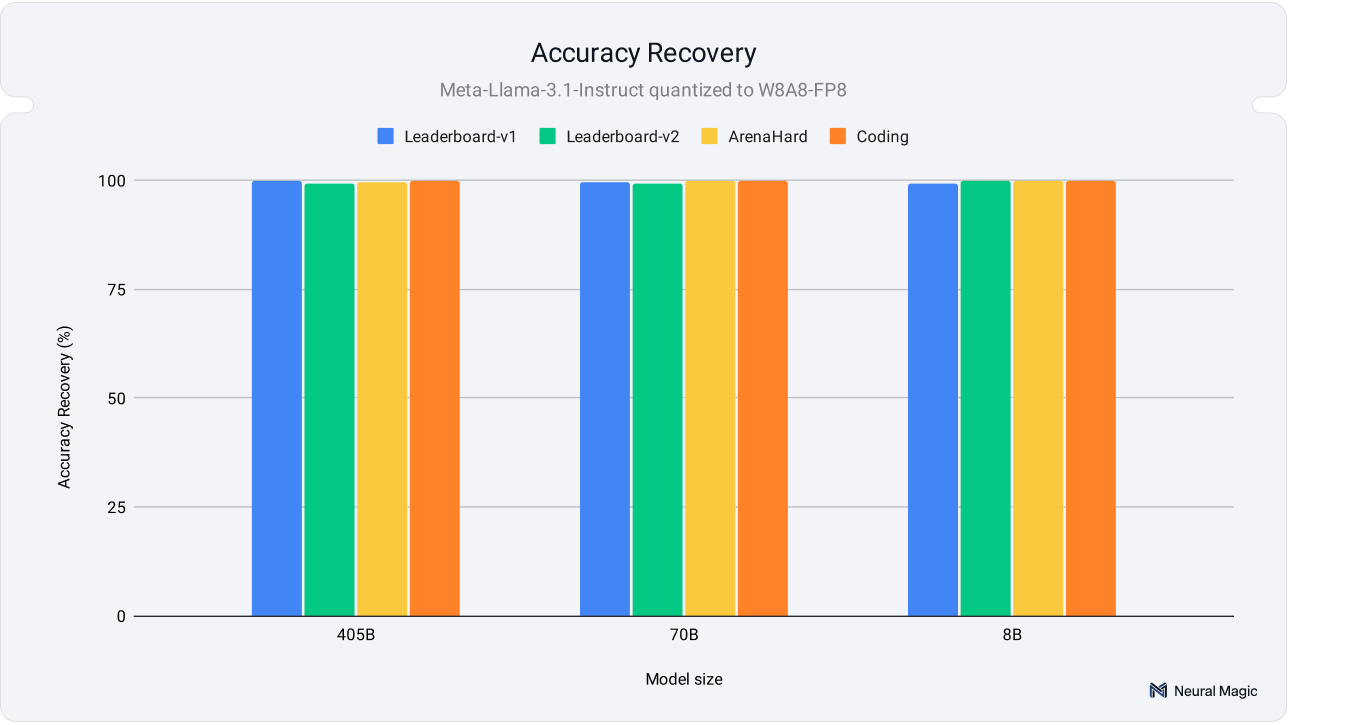
模型量化对模型精度影响的研究
编译程序
·

边缘AI的前景与有效采用的方法
KDnuggets
·

LLM 推理和应用 开源框架梳理 - JadePeng
博客园 - JadePeng
·
