

一分钟读论文:《可扩展 LLM 驱动多智能体系统的设计原则》
Micropaper
·

Text-only LLM SFT 训练数据预处理:从收集到数据打包的完整指南
亚马逊AWS官方博客
·

Token-budget-aware LLM reasoning: cut costs in 2026
Redis Blog
·

Python 潮流周刊#160:AI 智能体与 LLM 推理
豌豆花下猫 | Python猫
·
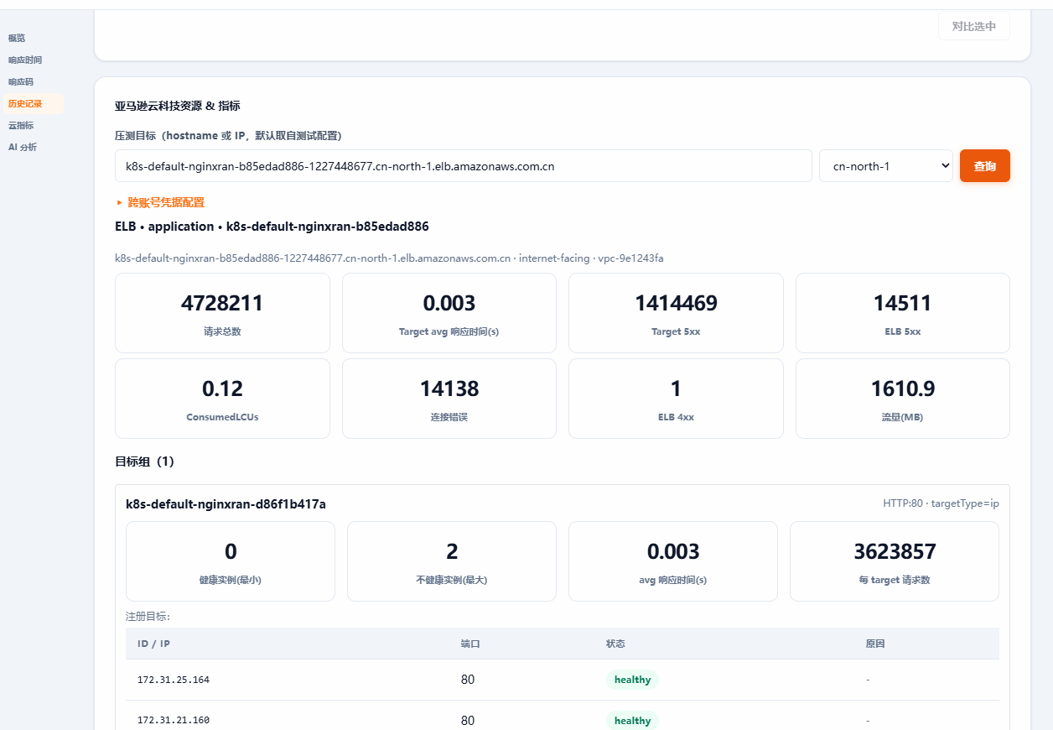

Why goodput matters more than throughput for LLM serving
Cloud Native Computing Foundation
·

LLM 与信息熵
sjdhome blog
·


基于回归的因果推断的产品实验:使用Python和statsmodels估计LLM特征影响
freeCodeCamp.org
·

Scikit-Ollama用于Scikit-LLM/Ollama集成
MachineLearningMastery.com
·

领域特定语言(DSL)促进大型语言模型(LLM)的可靠使用
Martin Fowler
·

LLM评估框架比较:如何实际衡量您的模型表现
MachineLearningMastery.com
·
